Claude Codeで10本のSEO記事リライトを一人で回した話|AIエージェント分業の実例

「AIで業務を自動化する」という話を聞くとき、多くの人が思い浮かべるのはChatGPTに質問して回答を得るような使い方だと思います。一問一答、その場限り、結果は人間が手作業で次の工程へ運ぶ。便利ではありますが、これは「業務の自動化」とは少し違います。
本当の業務自動化は、複数の専門エージェントが役割分担して、工程の最初から最後まで流れることです。企画を立てるエージェント、原稿を書くエージェント、品質をチェックするエージェント、システムに反映するエージェント——それぞれが自分の仕事をこなし、成果物を次の工程に渡していく。これができて初めて、「人間が最終確認だけする」というレベルの効率化が実現します。
私は最近、この形の業務自動化を実際に試す機会がありました。具体的には、専門性の高いSEOサイトで、10本の記事を順次リライトしていくというプロジェクトを、Claude Codeとサブエージェント機能を使って一人で回しました。本記事では、その実装の設計と、実際に動かしてみて分かったことを、業種を問わず応用可能な形で共有します。
これまでの記事で「AI時代の組織設計」や「AIエージェントを社員として扱う」という話を書いてきましたが、今回はその実装編です。抽象論ではなく、実際にコマンドを叩いて業務を回した記録として読んでもらえればと思います。
この記事の結論
- 業務自動化の本質:単一AIに全部やらせるのではなく、工程別の専門エージェントに分業させる設計が効く
- 3種類のエージェント:原稿作成/専門チェック/CMS反映の3役で分業。書くAIとチェックするAIを分けることで独立監査が成立する
- 知識の永続化:プレイブック(計画書)+wiki(横断ノウハウ)+進捗ファイルの3点セット。毎回のブリーフィングコストがゼロになる
- 標準フロー:着手決定→原稿作成→専門チェック→3段階反映→進捗更新の5ステップ。1記事あたり実働2〜3時間
- 3段階デプロイ:ローカル→ステージング→本番。事故を「気合い」ではなく「仕組み」で防ぐ設計
- 応用:分業設計・知識永続化・リスク管理の3要素はどの業種でも通用する
前提:Claude Codeとサブエージェントについて
記事の本筋に入る前に、Claude Codeについて簡単に触れておきます。知っている方は次のセクションまで飛ばしてください。
Claude Codeは、Anthropic社が提供するAIコーディング支援ツールです。もともとは開発者がターミナルからClaudeに作業を依頼するためのツールとして作られました。ただ、現在はコーディングにとどまらず、ファイル操作・外部サービス連携・複数エージェントの協調まで扱える、広範なタスク実行環境に進化しています。
特に今回のプロジェクトで鍵になったのが、サブエージェント(subagents)という機能です。
サブエージェントとは、特定の役割に特化したAIアシスタントのことです。メインのClaudeが、タスクの種類に応じて適切なサブエージェントに仕事を委譲できる仕組みが用意されています。サブエージェントは自分専用のコンテキストウィンドウを持ち、独立した権限と道具を持って働くので、メインの会話を汚さずに専門的な処理をこなします。
例えば「この記事を医療観点でチェックして」と頼むと、メインのClaudeが自分でチェックするのではなく、医療チェック専門のサブエージェントに仕事を振ります。サブエージェントは自分の文脈で作業し、結果の要約だけを返してくる。人間の組織における「部署への業務依頼と報告」とほぼ同じ構造です。
この仕組みがあるから、今回のようなプロジェクトが一人で回せます。
プロジェクトの全体像
今回のプロジェクトは、専門性の高い分野のSEOサイトで、既存10記事を順次リライトして検索順位を改善する、というものでした。
現状の記事は、書かれた当時は良い内容だったものの、検索順位が下降傾向にある。文字数が足りない、最新の検索意図に合わない、構造化データが不足している、という典型的な「SEO老朽化」の症状です。
これを、月間想定流入を合算して5,000PV以上の上積みを狙う目標で、3ヶ月で10記事をリライトする、というスケジュールを組みました。
なぜ分業設計が必要か
10記事を一人で書くとなると、単純計算で1記事あたり数時間×10本。でも、実際にはそれだけでは終わりません。
- 現状の記事の分析(何が足りていないか)
- 検索上位記事の調査(何が求められているか)
- 原稿の作成
- 専門観点でのチェック(ここが重要。後述)
- CMSへの反映
- 構造化データ(JSON-LD)の実装
- ステージング環境での動作確認
- 本番反映と検証
各工程が数時間〜半日かかるものもあり、10記事を直列でやると普通に数ヶ月〜半年のプロジェクトになります。
ここで、工程ごとに専門エージェントを用意して分業させる設計にすれば、以下のメリットが得られます。
- 各エージェントがその工程に最適化された指示を持てる
- メインの会話が工程の切り替えごとにリセットされないで済む
- 専門チェックをダブルチェックの仕組みとして組み込める
- 知識をプレイブックとwikiに蓄積して、次回以降を速くできる
これ、規模感が違うだけで、中小企業が専門スタッフを雇って業務を分担するのと同じ構造です。
分業設計——3種類のエージェント
今回のプロジェクトで主に使ったサブエージェントは、役割別に3つです。
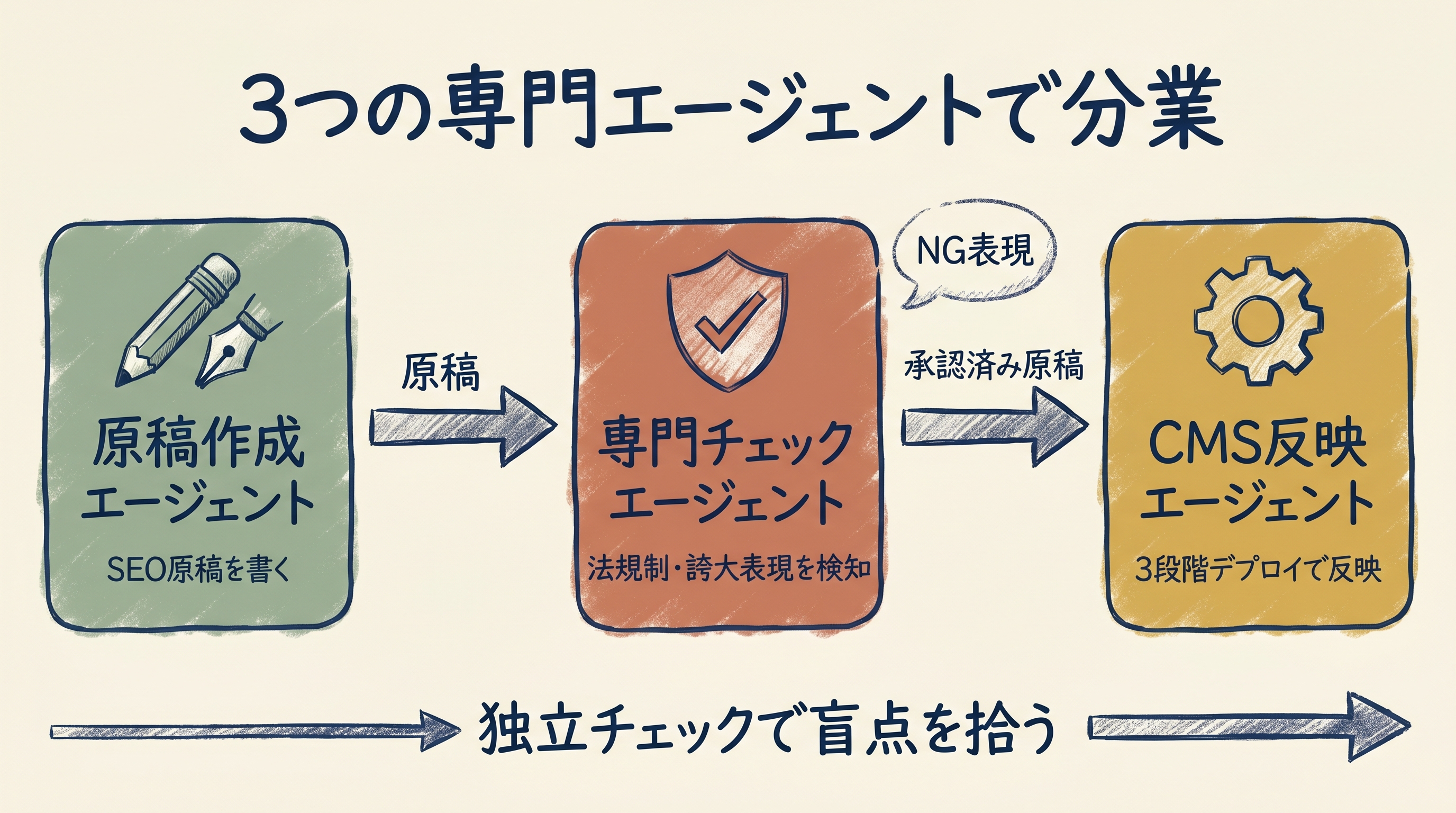
エージェント1:原稿作成エージェント
SEO記事の原稿作成に特化したエージェントです。このエージェントには、以下のような知識と制約を持たせます。
- ターゲットキーワードとユーザーの検索意図
- 検索上位記事の構成パターン
- SEO観点での必須要素(H2構成、FAQ、即答文、内部リンク等)
- 文字数の目安と構造化データの要件
このエージェントは、「リライト対象のキーワードと現状URLを与えると、改訂原稿のMarkdownを返す」という形で動きます。自分のコンテキストで上位記事を調べ、現状記事と比較し、改善版を作る——これを全部一つの会話にまとめずに、独立して処理してくれる。
エージェント2:専門チェックエージェント
ここが今回の設計で最も重要な部分です。
専門性の高い領域のSEO記事は、法的・倫理的に踏み込んではいけないラインが存在することが多いです。例えば、健康・医療・金融・法律・教育といった「YMYL領域」(Your Money or Your Life=人生に重大な影響を与える領域)と呼ばれるジャンル。ここで不正確な情報や誇張表現を書くと、事業リスクに直結します。
そこで、原稿作成エージェントとは別系統の専門チェックエージェントを立てて、原稿を必ずこのエージェントに通す設計にしました。チェックエージェントは、その業界特有のNG表現・誇大表現・法規制抵触の可能性を検知するよう調整してあります。
重要なのは、原稿を書くエージェントと、チェックするエージェントを別にすること。以前の記事「AI時代の組織に必要な3つの原則」でも書いた「二つの目で独立チェックする」原則の実装です。同じエージェントが書いて同じエージェントが確認するのは、自分の書いた稟議書を自分で承認するようなもの。別系統のエージェントに評価させることで、盲点を拾えます。
エージェント3:CMS反映エージェント
原稿ができて、チェックも通ったら、次はCMS(コンテンツ管理システム)への反映です。これもまた別のエージェントの仕事にしました。
このエージェントは、以下を担当します。
- ローカル環境での記事更新(まずは自分のPC内で)
- ステージング環境への反映(テスト用の別サイト)
- 構造化データの実装(テーマファイルへの追記)
- バックアップの取得(本番反映前に必ず)
- 本番反映と検証(外部からアクセスして確認)
CMSの操作はコマンドラインでの操作が多く、ミスが事故に直結する領域です。原稿を書くのが得意なエージェントに任せると、かえって危険。CMS操作に特化した、制約の多いエージェントに任せるほうが安全です。
このエージェントには、「本番環境に直接書き込みする前に、必ずバックアップを取る」という動作ルールを組み込んであります。これは人間のオペレーターでも忘れがちな手順ですが、エージェントの標準動作に組み込めば、毎回確実に実行されます。
知識の永続化——プレイブックとwiki
分業設計と同じくらい重要なのが、プロジェクトで得た知識を永続化する仕組みです。
Claude Codeで一つのタスクを実行しても、そのセッションが終わると、基本的には文脈は消えます。次のセッションでは、また最初から説明し直すことになる。これでは、毎回一からやり直しの新人と仕事をしているのと同じです。
これを防ぐために、プロジェクトの最初にプレイブック(実行計画書)を作り、進行中に得た知見をwiki(知識ベース)に蓄積していく運用にしました。
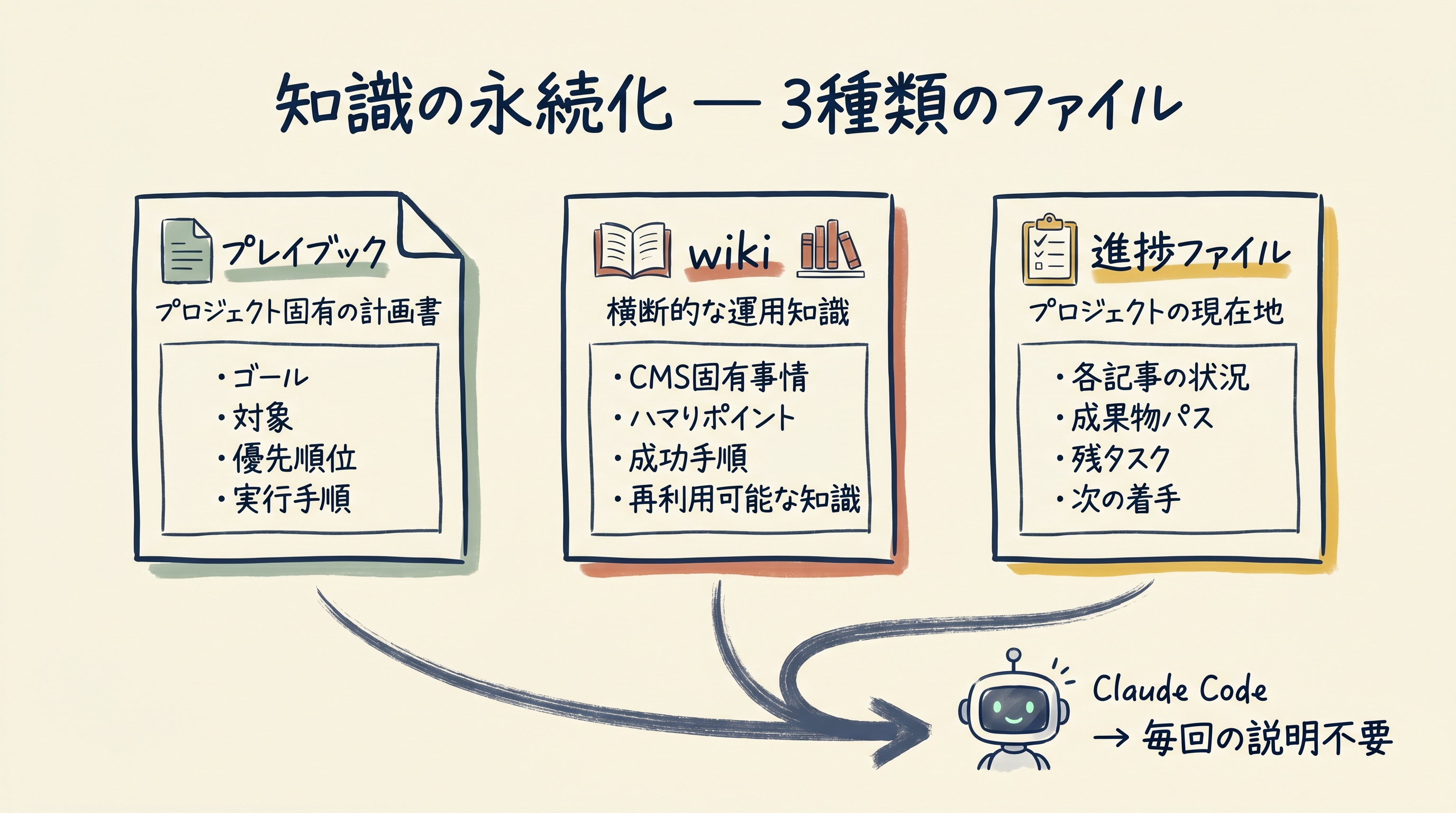
プレイブックとは
プレイブックは、プロジェクトのゴール・対象・優先順位・実行手順をまとめた設計書です。今回のプロジェクトでは、以下のような内容を1つのMarkdownファイルにまとめました。
- プロジェクトの背景(なぜこの10記事か)
- 各記事の現状データ(キーワード、現順位、文字数、URL)
- 優先順位とフェーズ分け(どの記事から着手するか)
- 各記事の目標(目標順位、文字数の目安)
- 実行フローの標準手順(原稿作成→チェック→CMS反映の具体ステップ)
このファイルを、Claude Codeがプロジェクトの起点として毎回参照する設計にしてあります。新しいセッションで「このプロジェクトの続きをやろう」と言うと、まずプレイブックを読んで全体像を把握してから作業に入る。毎回のブリーフィングを省略できます。
wikiとは
wikiは、業務ノウハウの横断的な蓄積場所です。プレイブックが「このプロジェクト固有の計画書」なら、wikiは「複数プロジェクトで使い回せる運用知識の集積」です。
今回の例で言えば、使っているCMSの固有事情、構造化データの投入方法、本番サーバーの環境仕様、ハマりやすい落とし穴——こういう情報をwikiに蓄積しておくと、別のサイトで同じような作業をするときに即座に再利用できる。
重要なのは、wikiは目次を最初に読むだけにして、詳細は必要になったときに読み込むという設計にすること。最初から全てを詰め込むと、コンテキストが肥大化してコストが上がります。図書館の目録と同じで、「どこに何があるか」だけを最初に把握し、必要な本だけを取り出す。この設計にすると、長いセッションでも効率が落ちません。
進捗管理ファイル
もう一つ重要なのが、進捗を記録するメモリファイルです。これは「プロジェクトの現在地」を記録するためのもので、以下を含めます。
- 各記事の着手状況(未着手/作業中/完了)
- 完了した記事の成果物へのパス
- 未解決の課題や残タスク
- 次に着手すべき記事と理由
このファイルを、記事を一つ仕上げるたびに更新する運用にしてあります。こうすると、1ヶ月後、2ヶ月後に続きをやるとき、「どこまでやったっけ?」と思い出す手間がゼロになる。中小企業で、担当者が変わるたびに引き継ぎに時間がかかる問題、これで丸ごと解決します。
実行フロー——1記事を仕上げる標準手順
ここまでの設計を踏まえて、実際の1記事リライトの流れを見ていきます。
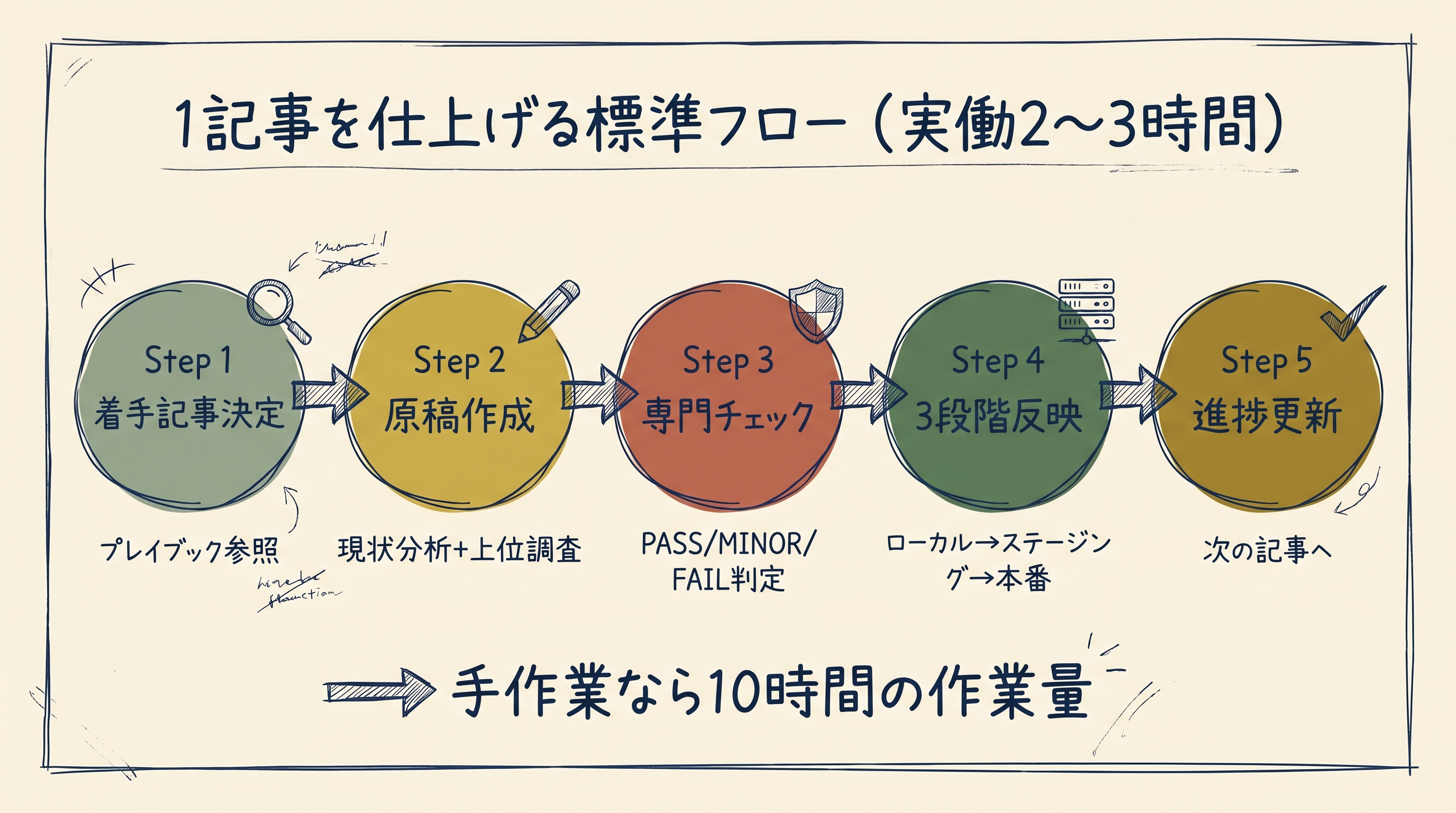
ステップ1:着手する記事を決める
プレイブックと進捗ファイルを参照して、次に着手する記事を決めます。優先順位は事前に決めてあるので、基本は順番に進めるだけ。このステップに判断の余地はほぼありません。
ステップ2:現状分析と原稿作成
原稿作成エージェントに、対象記事のURLと現状のキーワード順位を渡します。エージェントは:
- 現状記事を取得して構造を分析
- 検索上位記事を調査して不足要素を特定
- 改訂原稿のMarkdownを作成
この作業は、メインのClaudeセッションで直接やらず、サブエージェントに委譲するのがポイント。そうすることで、メインのコンテキストには「改訂原稿のMarkdown」という結果だけが返ってくる。上位記事の調査で読んだ大量の内容は、サブエージェントの中で消化されてメインには残りません。
ステップ3:専門チェック
出来上がった原稿を、専門チェックエージェントに渡します。返ってくるのは、以下のような判定。
- PASS:そのまま本番反映OK
- PASS_WITH_MINOR_FIXES:軽微な修正で通る
- FAIL:大幅な書き直しが必要
大半の原稿は、MINOR_FIXES判定で、具体的にどの表現を直すべきかのリストが返ってきます。原稿作成エージェントに、その修正指示を戻して再修正をかける。2〜3回のキャッチボールで、本番レベルの原稿に仕上がります。
ステップ4:ローカル→ステージング→本番の3段階反映
原稿が確定したら、CMS反映エージェントに渡して反映を指示します。ここは「3段階デプロイ」の設計になっています。
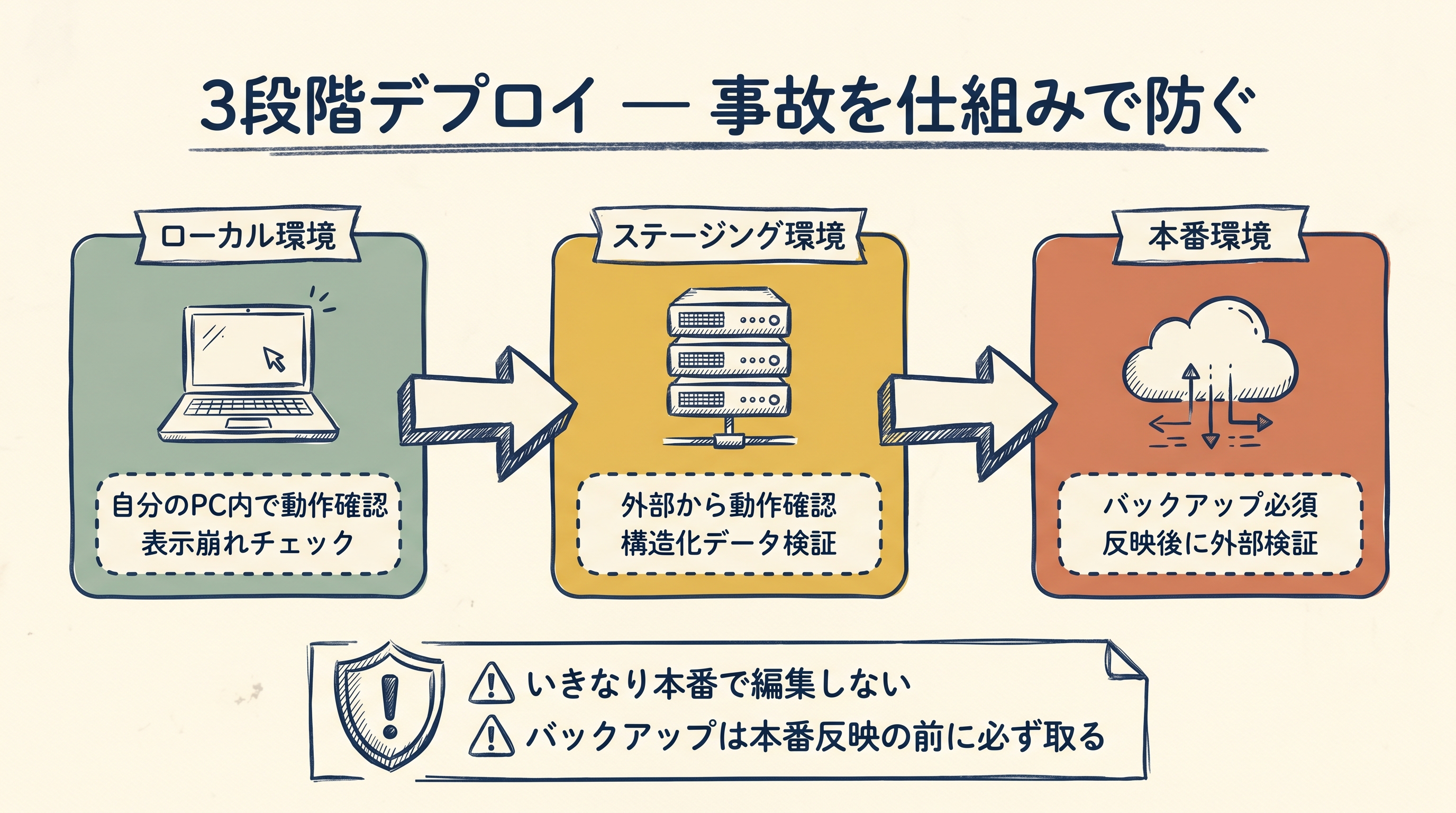
第1段階:ローカル環境
自分のPC内に立ててある、本番と同じ構成のCMS環境で、まず更新を試します。ここで動作確認をし、表示崩れや構造化データのエラーがないか確認。
第2段階:ステージング環境
本番とほぼ同じ構成で、外部には公開していない別サイトに反映します。ここでは、外部からアクセスして動作確認できる。本番に出す前の最終確認の場です。
第3段階:本番環境
すべて問題なければ、本番に反映。反映前に必ずバックアップを取り、反映後に外部から見て意図通りに表示されているか確認します。
この3段階を、CMS反映エージェントが自動で順番に実行する設計にしてあります。人間は最後の「本番反映」の指示だけ出せばよい。中小企業で起きがちな「いきなり本番で編集して事故る」リスクを、構造的に排除できます。
ステップ5:進捗ファイルを更新
最後に、進捗ファイルを更新します。今回仕上げた記事のステータスを「完了」に変え、成果物のパスを記録し、次に着手する記事を確認する。これで1サイクル終了です。
1記事あたり、この全フローで実働2〜3時間程度。手作業で全部やっていたら、軽く10時間はかかる作業量です。
実際に動かしてみて分かったこと
理論はここまでです。ここから先は、実際にこの仕組みを動かして気づいたことを共有します。
想定通りに動いた部分
プレイブック+wikiの威力が想像以上でした。プロジェクト開始から2週間ほど経った時点で、Claude Codeに「このプロジェクトの続きを進めよう」と言うだけで、プレイブックを読んで現状を把握し、次のアクションを提案してくれる。文脈の引き継ぎコストがほぼゼロになります。
これは中小企業で言えば、ベテラン社員が毎朝「昨日の続きからやりますね」と迷わず仕事を始めるのと同じ状態。業務が属人化せず、誰が(どのAIセッションが)続きを引き継いでも、同じ品質で進められる。
想定外に効いた部分
専門チェックエージェントの「厳しさ」が、想像以上に価値を生みました。原稿作成エージェントは、放っておくと多少踏み込んだ表現を使います。法的にギリギリ、あるいはアウトの可能性がある表現も含めて。それを、専門チェックエージェントが毎回容赦なく引き戻す。
結果として、人間が書くよりも安全な原稿になる。人間だと「これくらいは許容範囲かな」と曖昧に判断してしまう表現を、機械的にNGとして指摘してくれる。コンプライアンスの観点で言うと、AIのほうが人間より厳格に働いてくれるという逆転現象が起きます。
想定外に難しかった部分
一方で、3段階デプロイの設計は、当初想定より細かい調整が必要でした。本番サーバーの固有事情(環境のバージョン違い、プラグインとの相性、テーマの挙動)が、想像以上にトリッキーで、wikiに蓄積する知識量がどんどん増えていきました。
ここで気づいたのは、業務自動化で本当に大事なのは、自動化の対象ではなく、その周辺の固有事情を蓄積する仕組みだということ。中小企業で業務をAI化するとき、最大の障壁は「AIが使えるかどうか」ではなく「自社固有の文脈を、どうAIに教え続けるか」なんです。
中小企業経営者として押さえるべき5つのポイント
この実装事例から、中小企業経営者が自社で応用するときの要点を5つに絞って整理します。
一つ目は、「AIで自動化する」とは「1つのAIに全部やらせる」ではなく「複数のAIに分業させる」こと。単一のAIに何でもやらせると、結果の質がブレます。工程ごとに専門エージェントを用意する発想を持つと、品質が安定します。
二つ目は、書くAIとチェックするAIを分けること。これは前の記事でも書いた「二つの目で独立チェック」の原則そのもの。特にコンプライアンスが重要な業種では、必須の設計だと思います。
三つ目は、プレイブック(設計書)を最初に作ること。プロジェクトのゴール、対象、優先順位を明文化する。これがないと、AIに毎回同じ説明をすることになり、効率が上がりません。「AIに説明するため」ではなく、「事業として必要だから」書く。結果的にAIにも使える、という順序です。
四つ目は、wikiに運用知識を蓄積すること。自社固有のハマりポイント、うまくいった手順、失敗した対処——これを継続的に書き足す。単発のセッションで失われていた知識が、組織の財産として積み上がります。
五つ目は、本番環境への直接操作を設計で禁じること。ローカル→ステージング→本番の3段階を、人間の気合いではなく仕組みで強制する。事故は「うっかり」で起きます。仕組みで防げば「うっかり」も起きません。
業務自動化の本質は、組織設計に限りなく近い
今回のプロジェクトを振り返って一番感じるのは、AIエージェントを使った業務自動化は、技術の話というより組織設計の話だということです。
どのエージェントにどの権限を持たせるか、どの工程で独立チェックを入れるか、どう知識を蓄積するか、本番操作の安全策をどう設計するか——これ、全部人間の組織でも議論される論点です。違いは、登場人物がAIだというだけ。
だからこそ、良い組織を作るのが得意な経営者は、AI業務自動化も得意になれると改めて実感しました。逆に、自社の業務分担が曖昧で、誰が何をやるかが定まっていない組織は、AIを入れても同じ曖昧さが再現されるだけ。AIに業務を任せる前に、そもそも「どう分業すべきか」を整理することが、すべての出発点になります。
今回の10記事リライトプロジェクトは、実装レベルで言えばニッチな事例ですが、分業設計・知識永続化・リスク管理という3要素は、どの業種でも通用するはずです。自社で「AIで業務効率化したいが、どこから手をつけたらいいか分からない」と感じている方は、まず自社の一つの業務プロセスを、エージェント分業の視点で書き出してみることから始めてみてください。
ここまでやると、AIの話ではなく、自社の業務設計の解像度が上がっている自分に気づくはずです。そしてそれこそが、AI時代の経営者に求められている本当のスキルだと、私は思っています。
関連記事
この記事のテーマに合うサービス:AIエージェント活用設計
AIエージェントを「使える形」まで設計する



