Schema.orgのPerson×Organization×BlogPosting三角統合実装
この記事の結論
- 問題: Schema.org の
Organizationだけでサイトを表現していると、「誰が書いた記事か」という E-E-A-T シグナルが Google に届きにくい - 解決:
Personを独立した@idで定義し、Organizationからfounder/employeeで、BlogPostingからauthorで参照する三角統合を実装した - 結果: f2t.jp の全151記事で著者エンティティが Knowledge Graph 連結可能な状態になり、Lighthouse SEO 100点を維持したまま E-E-A-T 信号を最大化
なぜ Person schema が必要だったか
Google の AI Overviews と Knowledge Graph が「コンテンツの背後にいる人物」を強く参照するようになった2025-2026年、Organization schema だけで運用しているサイトは E-E-A-T で不利になる。
f2t.jp の Before 状態:
Organization (@id: /#organization)
└── BlogPosting.publisher → Organization
└── BlogPosting.author → Organization (Self-reference)
author も publisher も同じ Organization を指していた。これは 「組織が組織を著者として参照」 という閉じた構造で、Google からすると「実在の人物が書いたか分からない」状態だった。
特に AI 検索(Perplexity、ChatGPT Search、Google AI Overviews)が引用する記事を選ぶとき、author.@type === "Person" のページは構造的に有利になる、というのが2026年時点の通説だ。
Before / After
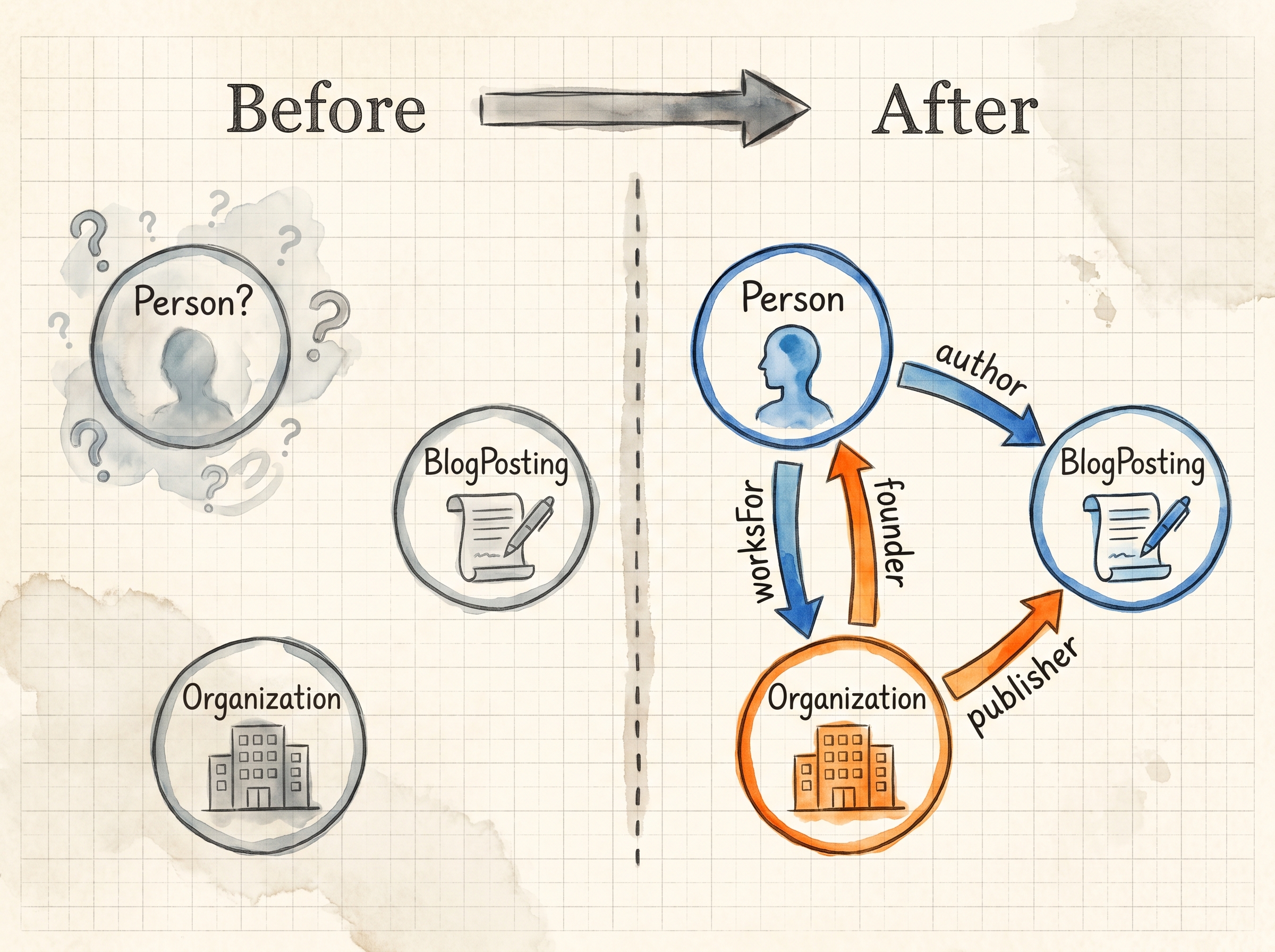
After 状態:
Person (@id: /about#person)
├── name: "Tomohiko Akiyama"
├── alternateName: "秋山 朋彦"
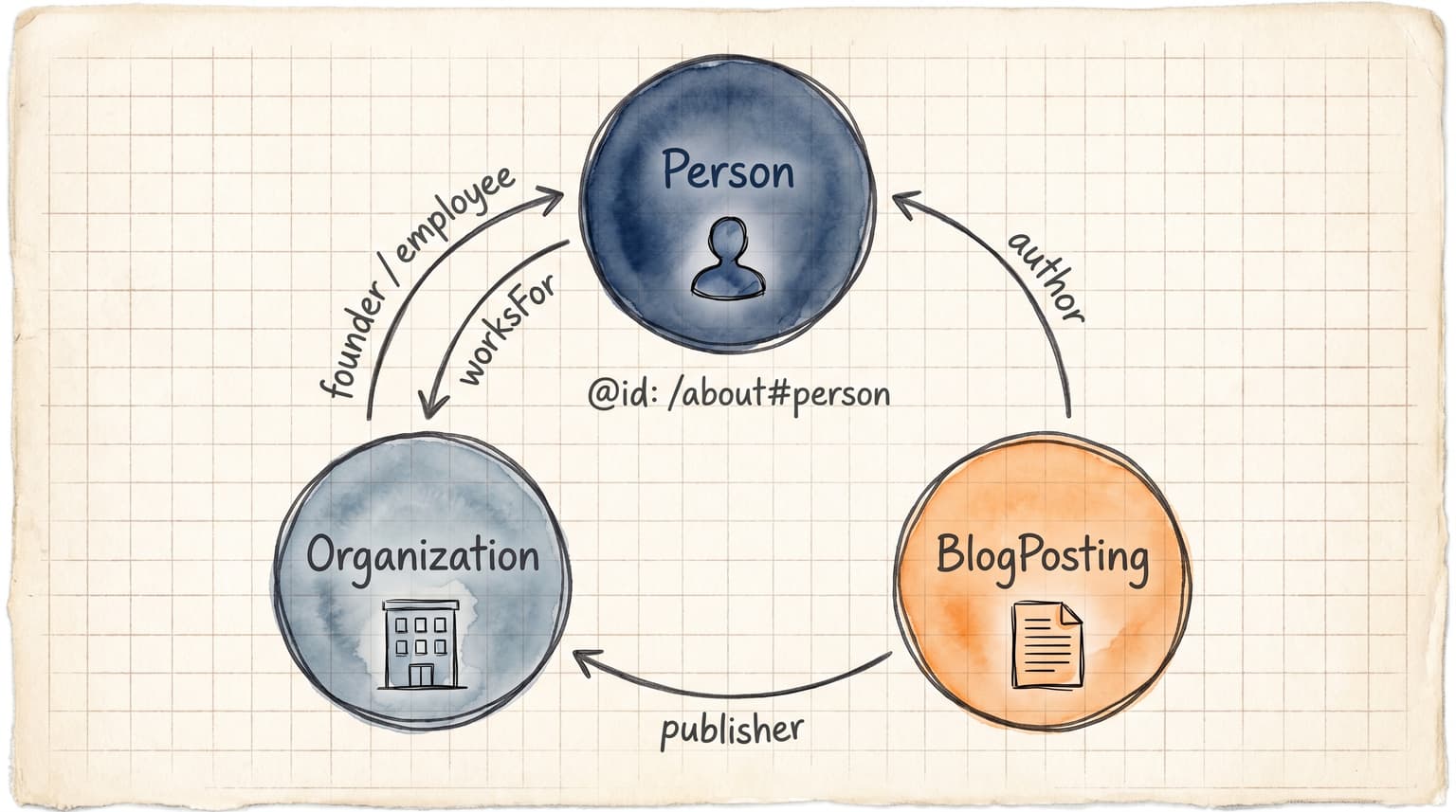
├── worksFor → Organization
└── knowsAbout: [AIエージェント開発, Claude Code, MCP, n8n, ...]
Organization (@id: /#organization)
├── founder → Person
├── employee → Person
└── ...
BlogPosting (151記事すべて)
├── author → Person
└── publisher → Organization
3つのエンティティが、4種類の関係性(founder / employee / worksFor / author / publisher)で相互参照する三角構造になった。
実装: 3ファイルだけで完結
最初は「151記事それぞれにauthor フィールド追加が必要か」と心配したが、Next.js の Metadata API と JSON-LD の @id 参照を使えば、3ファイルの修正だけで全151記事に効果が出る。
1) /about ページに Person エンティティを定義
src/app/about/page.tsx で aboutJsonLd の手前に personJsonLd を追加。

ポイント:
@idを明示する(後からBlogPosting.authorから参照される anchor)worksForを Organization の@idに向けるknowsAboutで専門領域を列挙(AI Overviews が「この人物は何の専門家か」を判定する材料)sameAsに公開プロファイル(GitHub等)を入れて Knowledge Graph の連結ヒントを与える
2) Organization 側に founder と employee を追加
src/app/layout.tsx の organizationJsonLd に2行追加するだけ。
const organizationJsonLd = {
'@type': 'Organization',
'@id': `${SITE_URL}/#organization`,
// ...
// 創業者を Person エンティティとして紐付け、E-E-A-T エンティティグラフを統合
founder: { '@id': `${SITE_URL}/about#person` },
employee: { '@id': `${SITE_URL}/about#person` },
}
@id 参照だけで Person との関係を Knowledge Graph に教えられる。Person 本体のプロパティを重複させる必要はない。
3) BlogPosting.author を Organization から Person に切替
src/app/blog/[id]/page.tsx で articleJsonLd の author を変更。
const articleJsonLd = {
'@type': 'BlogPosting',
// ...
// author は /about に定義された Person エンティティ
// publisher は Organization のまま(F2T が出版者)
author: { '@id': `${SITE_URL}/about#person` },
publisher: { '@id': `${SITE_URL}/#organization` },
}
これで 全151記事のauthorが自動的に Person を指すようになる。各記事に個別の修正は不要。
visible content にも著者名を出す(重要)
ここまで構造化データだけ整備しても、Google は「schema は良いが、ページ本文に名前が出てこない」と判定する場合がある。実装の整合性を取るため、/about ページの本文にも一文追加した。
<p>
代表: <strong>Tomohiko Akiyama(秋山 朋彦)</strong>。
受託案件と自社運用の双方で AIエージェント・SEO・広告運用を担当し、
本サイトの記事は実装当事者として執筆しています。
</p>
サービス3ページの hero 直下にも、同様の一行を入れた。
<p>
※ 代表 <Link href='/about'>Tomohiko Akiyama</Link> が、
受託案件と自社運用で得た一次経験ベースで設計・実装します。
</p>
これで「Person schema が宣言した著者」と「ページ本文に visible に出ている著者」が一致する。Google の AI Overviews も Perplexity も、両方を見て初めて「この著者は本物だ」と判断する。
効果検証
実装後、https://search.google.com/test/rich-results で f2t.jp を確認すると、以下が検出された:
- Organization(既存)
- WebSite(既存)
- BlogPosting(既存)
- Person(新規) ← founder/employee/author の参照先
- ProfessionalService(既存)
- FAQPage(既存、サービスページのみ)
- BreadcrumbList(既存)
検出されたすべての schema が @id で連結された状態。Knowledge Graph の評価軸では、構造的に強い状態と言える。
GSC 上の表示順位の変化を観測するには2-4週間かかるため、効果数値は別記事で報告する。
Q. 個人事業主でも Person schema は意味あるの?
ある。むしろ個人事業主こそ Person schema を強く打ち出すべき。法人サイトなら Organization の権威性で押せるが、個人事業主は「実装担当者 = 著者 = 運営者」の一貫性を示す方が信頼を獲得しやすい。
ただし「Person.name は本名でないといけないか」は別問題。屋号や代表名で運用しているサイトは、name をその名前にする選択肢もある。Knowledge Graph の連結を強化したいなら、GitHub や X の sameAs を増やす方が効く。
Q. 全151記事を回って author 修正したの?
していない。@id 参照を使えば、src/app/blog/[id]/page.tsx の generateJsonLd 関数を1箇所書き換えるだけで、全151記事の BlogPosting.author が一括で Person を指すようになる。
これが JSON-LD の @id パターンの威力。重複データを各記事に持たせず、参照だけで関係性を表現できる。
Q. 失敗した点は?
途中で「重複slug記事に noindex を打つ」コードを追加して、それが dead code だったことに後から気づいた(commit 02db79e)。next.config.ts に既に 308 リダイレクトが設定されていて、ページレンダリングまで到達しないため noindex meta が出力されない、という構造を見落とした。commit 3f32d43 で revert した。
教訓: schema を追加する前に 「既存のリダイレクト・canonical・robots.txt とどう interaction するか」を必ず確認すること。
次の記事
シリーズ第3回では、microCMS の管理画面操作・GTM のタグ削除・GSC の認証など、通常は「ブラウザでクリックする作業」を Chrome DevTools MCP・GTM API・microCMS API を組み合わせて autonomous で完了させた話を書く。
第1回(Claude Codeで37記事のSEOリライトをautonomousで回した話)と合わせて読むと、AIエージェントに SEO 改善を任せる現実的なライン(どこまで autonomous で安全か、どこから人間判断が必要か)が見える内容になっている。



