Claude Architect試験対策アプリを初心者向けに改修した4層設計
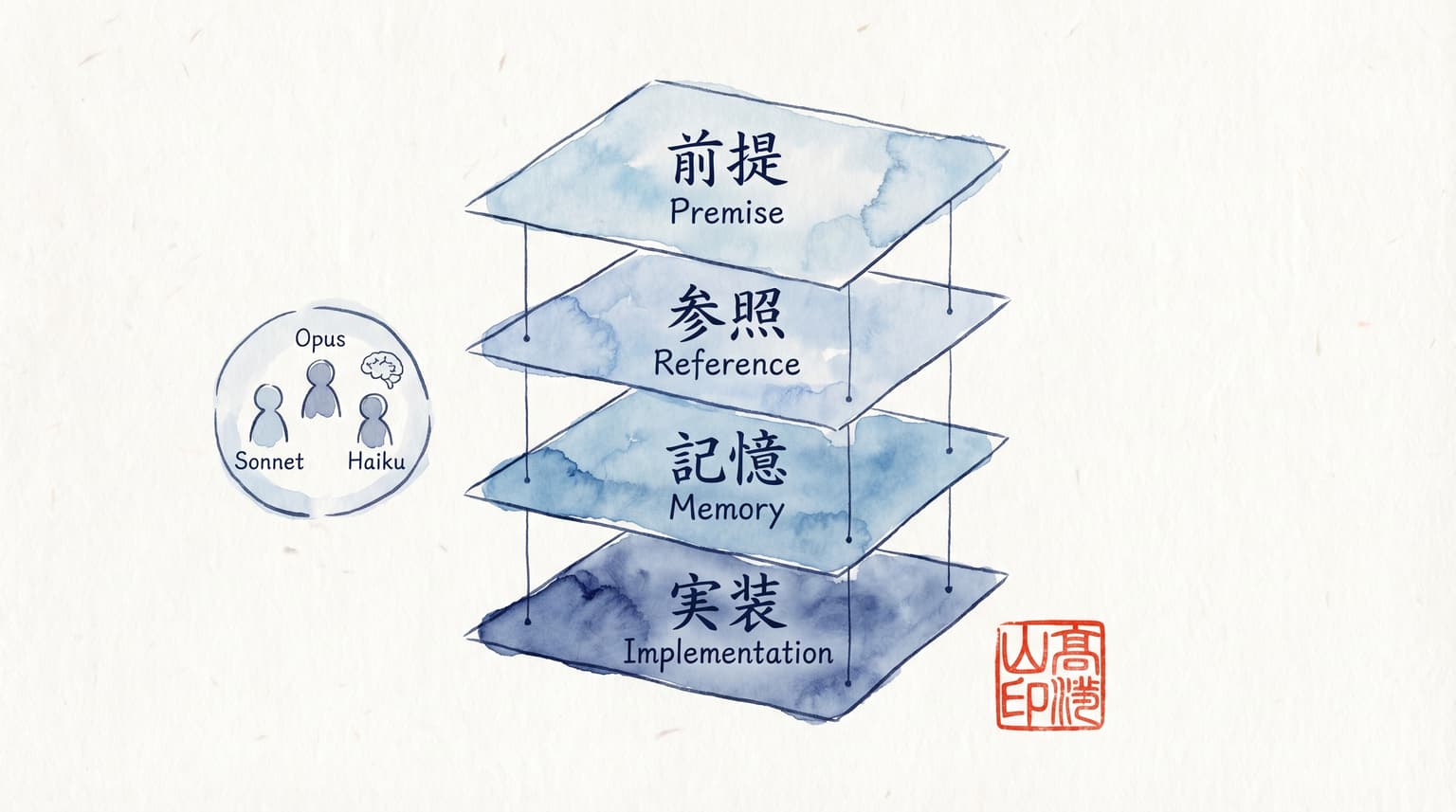
Claude Architect試験対策として作っている単一HTMLの学習アプリを、一晩で初心者向けに書き直した。作業時間は4時間。ゼロ章1章、用語集42語、ポイント集3節、水彩風の図解9枚、CSS修正1箇所。Git管理なしの個人プロジェクトで、編集したファイルは index.html 1本だけ。この記録から引き出した原則は「前提・参照・記憶・実装の4層」と、それを支える「差分追加・視覚ID統一・セッション復旧」の3つのパターンである。試験対策アプリに限らず、技術ドキュメントを非エンジニア向けに開く局面で転用できる設計メモとして残しておく。
この記事で扱う内容
- 技術教材を初心者に開くための4層フレーム
- Claude Code + nano-banana-pro を使った単一HTML改修の具体
- 既存コンテンツに手を入れず外側だけで改修する設計パターン
- 9枚の図解で視覚記憶をトピック識別子として使う方法
- Claude Code セッションが凍結したときのトランスクリプト復旧手順
対象読者は、Claude Architect試験を受ける学習者、Claude Codeで学習教材を作っている人、そして非エンジニア向けの技術ドキュメントを設計する立場の人である。
技術教材を初心者に開くには4層がいる
結論から言うと、技術教材を初心者に開くには4つの層が必要になる。どれか1つでも欠けると読者はそこで脱落する。
層 | 役割 | 今回の実装 |
|---|---|---|
層1 前提 | 物語に入る前に言葉の地図を渡す | ゼロ章(6セクション、読了8分) |
層2 参照 | 詰まった瞬間にその場で引く | 用語集パネル(42語、7カテゴリ) |
層3 記憶 | 一目で全体構造を思い出す | 水彩風の図解9枚 |
層4 実装 | 概念だけでなく動くコードを見せる | 試験ポイント集⑥⑦⑧の3節 |
ゼロ章だけ足しても本編に戻った瞬間に知らない語が出てくる。用語集だけ足してもそもそも何を引けばいいかわからない。図だけ足しても文字ベースの概念整理は代替できない。コードだけ見せても抽象の土台がない。4層が揃って初めて、プログラミング未経験者が最後まで辿れるルートができる。
改修対象のアプリ構成
改修の出発点を共有しておく。
対象は5200行を超える index.html で、CSSもJSも埋め込み、外部依存なしで動く。物語形式の8章と、Hooks、Agentic Patterns、Prompt Caching、Model Selection、Prompt Injection の5本からなる試験ポイント集を持っている。本編は storyMeta 配列と storyContent オブジェクトで章を管理し、ポイント集は page-addendum という静的HTMLセクションで別建てになっている。
Anthropic公式コース4本(Claude 101 / Building with Claude API / Intro to MCP / Claude Code in Action)が扱う内容は既存コンテンツでほぼ足りていた。ただLLMとは何か、トークンとは何か、エージェントとは何かという前提部分がすっぽり抜けていた。本編の1章はいきなり無限ループの実装話から始まる。プログラミング未経験者は2ページで脱落する構造だった。
層1 前提を整える章(ゼロ章)
ゼロ章の6セクション構成
- Claude とは何者か ── Anthropic が作るLLM。Opus / Sonnet / Haikuのモデル名
- トークンとコンテキスト ── 文字ではなくトークンで数える。コンテキストウィンドウの概念
- プロンプト ── AIへの指示文。System / User / Assistantのロール
- チャット vs エージェント ── Claude.ai と Claude Code の違い
- Claude Code とは ── ターミナルで動く自律的な相棒
- 用語の先出し紹介 ── 本編で頻出する10語を一言で定義
読了想定は8分。storyMeta 配列の先頭に要素を1つ足すだけで、既存の次章ナビゲーションに自動で乗る作りだった。ナビ側のコードはまったく触っていない。
前提層の設計原則
大事なのはゼロ章を入れる判断そのものより、物語に入る前にいったん言葉を整える切断面をどこに置くかだ。本編の1章の中で前提を補足する選択肢もあったが、前提知識を持っている読者にとっては冗長になる。別章として切り離しておけば、知っている人はスキップでき、知らない人はじっくり読める。前提層は本編と分離して置く、というのが4層設計の最初の原則である。
層2 詰まったときの参照(用語集パネル)
42語を7カテゴリに分けた
カテゴリ | 語数 | 代表例 |
|---|---|---|
Claude とモデル | 6 | Claude, Anthropic, Opus, Sonnet, Haiku, LLM |
トークンとコンテキスト | 5 | トークン, コンテキストウィンドウ, System prompt |
プロンプトとエージェント | 6 | エージェント, Chain of Thought, Few-shot |
ツールと外部連携 | 7 | ツール, MCP, stdio, tools/list, tools/call |
Claude Code の仕組み | 7 | サブエージェント, Hook, スラッシュコマンド, CLAUDE.md |
APIとプログラミング用語 | 6 | API, SDK, JSON, stop_reason, cache_control |
安全と信頼性 | 5 | Prompt Injection, 信頼境界, ガードレール |
各語には 語・読み・1文の定義 だけを持たせた。定義を1文で完結させたのは、画面上でパッと読めるだけでなく、検索エンジンやAI検索の引用単位としてそのまま使えるようにするためである。
UIパターン
画面右下にフローティングボタン(FAB)を固定で置き、押すと右から幅420pxのパネルがスライドインする定番の形にした。上部の検索欄で1文字入力するたびに data-term 属性でフィルタがかかる。Escキーでも閉じる。モバイルは全画面、デスクトップは420px固定。
集中して読んでいる最中にマウスで閉じるのとEscで閉じるのとでは、戻ってきたときの読書感がだいぶ違う。細かいが外せないディテールだった。
参照層の設計原則
- 本編から離脱しない。モーダルやオーバーレイにして既存のスクロール位置を保つ。
- 1項目が自己完結する。項目同士に依存がなければ、読者はどこからでも引ける。
層3 記憶に刺す視覚(9枚の図解)
生成した9枚
画像はすべて画像生成MCP nano-banana-pro で生成した。内訳は以下の通り。
# | トピック | 図の要素 |
|---|---|---|
1 | Hooks タイムライン | UserPromptSubmit → PreToolUse → PostToolUse の流れ |
2 | Agentic Patterns | 連鎖・振分・並列・動的・反復の5型グリッド |
3 | Prompt Caching |
|
4 | Model Selection | Haiku → Sonnet → Opus のカスケード |
5 | Prompt Injection | 鳥居(信頼境界)+4つの防御の盾 |
6 | Messages API | リクエスト/レスポンス構造 |
7 | MCP Server | 子プロセス+stdio+3つの棚(tools / resources / prompts) |
8 | Prompt Engineering | 6技法の2x3グリッド |
9 | LLM と3つのClaude | 確率予測器 + LLM/Claude.ai/Claude Code の三幅対(ゼロ章用2枚) |
統一ビジュアル言語
すべての図で以下を揃えた。
- 水彩 + 和紙のテクスチャ
- 日本語と英語のバイリンガルラベル
- 朱色の印判(視覚ID)
- 文字最小限、記号と配置で意味を作る
記憶層の設計原則
視覚の一貫性を内容の一部として扱う。朱色の印判が全図に共通して入っていると、読者は試験中にあの朱印の図はどのトピックだったかと記憶を手繰れる。ランダムなフリー素材の寄せ集めではこの効果は得られない。
これは手書き図とAI生成を混ぜなかった判断の根拠でもある。統一されたスタイルそのものがトピック識別子として働く以上、途中で画風が変わるとIDが壊れる。画風そのものを内容の一部として設計するというのが2つ目の原則である。
層4 動くコードを見せる実装(試験ポイント集⑥⑦⑧)
既存の試験ポイント集5節は概念と方針の説明に寄っていた。ここに3節を追加した。
⑥ API Messages 構文の基本
Python SDK の client.messages.create で動く最小例、ツール定義のJSON Schema、stop_reason として返ってくる end_turn / max_tokens / tool_use / stop_sequence を並べた。一度もAPIを叩いたことがない人がこのページだけ見て最初のリクエストを書ける、というところを文量の基準にした。
⑦ MCP サーバーの骨格
TypeScript で @modelcontextprotocol/sdk を使った最小構成。StdioServerTransport でサーバーを立て、tools/list と tools/call をハンドラで受ける形にした。あわせて .mcp.json の設定例も同じページに載せ、サーバー側のコードとクライアント側の設定が1画面で揃うようにした。
⑧ Prompt Engineering 6つの技
Anthropic 公式のプロンプトエンジニアリングガイドを6つに絞った。
- Be Clear & Direct
- Few-shot(例示プロンプト)
- Chain of Thought(思考の連鎖)
- Role(役割の付与)
- XMLタグ(構造化入力)
- Output Format(出力フォーマット指定)
それぞれ1行の効能と1つの実例で押さえた。試験では技法名と効能のペアが問われるので、2x3グリッドの図解と対応づけて覚えられる構成にしている。
実装層の設計原則
最小で動くものを1ページに閉じる。サーバー側と設定、コードと効能、手法と実例。対になる情報を別ページに分けて置くと、読者はページを往復するうちに何を探していたか忘れる。1画面で閉じれば読者はそこで止まって考えられる。
1セッションで3トラックを並列実装した
作業の進め方も記録しておく。3トラックを同時に走らせた。
トラック | 編集ゾーン |
|---|---|
ゼロ章追加 |
|
用語集パネル |
|
試験ポイント集⑥⑦⑧ |
|
1ファイルでも編集ゾーンがぜんぶ別だったので衝突しなかった。Edit ツールで順次流し込むだけで済んだ。この「1ファイル多ゾーン同時編集」パターンは、単一HTMLの教材やLPを改修するときに使える。
ハマったのは画像のはみ出しCSSバグ
<figure><img> を試験ポイント集のセクションに入れた瞬間、画像が自然サイズのまま右にはみ出した。ユーザーからスクリーンショットが即座に飛んできて気づいた。
原因は、画像の幅制約のCSSが .story-body figure img にしかスコープされておらず、ポイント集の #page-addendum セクションには一切当たっていなかったこと。本編では文字コンテンツしかなかったので、これまで露見していなかったバグだった。
/* Before */
.story-body figure img { width: 100%; max-width: 100%; height: auto; }
/* After */
.story-body figure img,
#page-addendum figure img { width: 100%; max-width: 100%; height: auto; }
修正はセレクタに #page-addendum figure img を並列追記するだけで済んだ。共通ユーティリティのクラスを切って両方に付けるほうがきれいだが、単一HTMLで完結させたい制約からこの決着にした。
教訓:画像系のCSSをコンポーネント単位にスコープすると、新しいセクションに画像を足したときにほぼ確実に忘れる。 開発中に気づければいいが、公開後だと恥ずかしい類のバグだ。
パターン1 差分追加型改修(外側だけ触る)
ここから先は、実装中に現れた3つのパターンを汎用化しておく。
1つ目は、既存コンテンツに一切手を入れず外側に足すだけで改修する進め方だ。本編8章と既存ポイント集5節には1文字も変更を加えていない。既存を信じて、その外側に入口と参照系と実装例を配置した。
この設計が効く理由は3つある。
- リグレッションリスクがほぼゼロになる。既存部分のテストを回す必要がない。
- 初心者モードが不評でも削除するだけで元に戻せる。実験コストが低い。
- 設計のときから自然と形が決まる。既存の軸を動かさない前提で考えると、ゼロ章は独立した章として分離される。用語集はモーダルになる。図解は
figureで差し込むだけで済む。追加3節は末尾に並ぶ。全部、外側に閉じる。
大規模な教材やドキュメントほど、内側を書き直すコストが跳ね上がる。外側に足すだけで機能を付け加えられる構造にしておくと、改修の心理的なハードルが下がる。このパターンは教材に限らず、長年運用されてきた社内ドキュメント、古いランディングページ、オンボーディング資料の改修にも転用できる。
パターン2 視覚の一貫性はトピック識別子になる
2つ目は、複数トピックを横断する教材では、図のスタイルが揃っていること自体が記憶の手がかりになるという話だ。朱色の印判というビジュアル要素が全図に共通して入っているだけで、読者はそれをトピック識別のインデックスとして使い始める。
逆に、スタイルが混ざった教材では、絵を見ても「これはどの章のものだったか」を思い出せない。AIが生成した画像と手書きのラフと写真素材を混ぜると、このIDが壊れる。
実装上はAI画像生成で揃えるのが楽だ。プロンプトの基礎部分(メディア、色調、視覚要素)を固定して、内容の部分だけ差し替える。nano-banana-pro のような画像生成MCPなら、1セッションで9枚以上を一貫した画風で量産できる。
生成ツールに何を使うかは二次的で、一次的な判断は「全部を同じ画風で揃えると決めること」である。
パターン3 セッション凍結からの復旧(トランスクリプトを読み直す)
3つ目は、Claude Codeセッションが凍結したときの復旧手順だ。これは Claude Code ユーザー全員に効く話なので、独立して書いておく。
この記事のベースになったセッションは実は2回目で、1回目は試験ポイント集の図解5枚を生成する途中で完全に固まった。復旧の手順はこうだった。
~/.claude/projects配下の.jsonlトランスクリプトをgrepで探すcwdフィールドから対象プロジェクトを特定する- 最後のユーザー指示と直前のツール呼び出しを読み直して、どこまで進んでいたかを確認する
- 出力ディレクトリ(今回は
images/)をglobで一覧し、何が既に生成されていて、何がまだかを突き合わせる - 新しいセッションで未完了分から再開する
ここで大事なのは、固まったセッションを蘇生しようとしないという判断だ。再接続や再送信を何度も試すより、別セッションでトランスクリプトを読み返して状態を再構築するほうが圧倒的に速い。
Claude Code のトランスクリプトはツール呼び出しとその結果を構造のまま保持してくれているので、作業の到達点は事後でも正確に復元できる。復旧は蘇生ではなく再構築だ、と覚えておけばいい。
まとめ ── 持ち帰れる4つの原則
1セッションで実装したのは以下の通り。
- ゼロ章1章(読了8分、6セクション)
- 用語集42語(7カテゴリ)
- 試験ポイント集3節(API / MCP / Prompt Engineering)
- 水彩風の図解9枚
- CSS修正1箇所
持ち帰れる原則は4つ。
- 技術教材を初心者に開くには前提・参照・記憶・実装の4層がいる。 どれか1つでも欠けると読者は脱落する。
- 既存に手を入れず外側に足すほうがリグレッションが出ない。 差分追加型改修は大規模ドキュメントでも転用できる。
- 視覚の一貫性そのものが記憶のインデックスになる。 画風を揃えることを内容の一部として設計する。
- セッションが固まったら蘇生せずトランスクリプトから再構築する。 Claude Code の
.jsonlは状態復元の最強の手がかりになる。
Claude Architect試験対策アプリに限らず、どんな技術ドキュメントでも同じ4層と3パターンで組み直せるはずだ。試験本番まではこのアプリで走る。物語で骨格を掴み、試験ポイント集で範囲を詰め、図解で視覚記憶に刺す。想定通り回るかは本番後に振り返って書き足す。
著者
akkin ── Claude Code を業務と個人プロジェクトの両方で日常使用しているエンジニア。f2t 運営者として、SEO・広告・マーケティング支援を行う。Anthropic の Claude Architect 認定試験に向けて本記事のアプリを開発している。
関連リンク
- Anthropic 公式ドキュメント Messages API
- Model Context Protocol 公式仕様
- Anthropic Prompt Engineering ガイド
- Claude Code 公式ドキュメント
この記事のテーマに合うサービス:AIエージェント活用設計
AIエージェントを「使える形」まで設計する



