BigQueryのタイムゾーンで月次集計がズレる。「同期欠損」と誤診した話

BigQueryのタイムゾーンで月次集計がズレる。「同期欠損」と誤診した話
元の業務ツールのダッシュボードでは「1月の件数はこれだけ」と出ているのに、BigQueryで同じ月を集計すると数件少ない。翌月は逆に数件多い。毎月ほんの少しずつ合わない。こういう経験はないでしょうか。
数件のズレだと、つい「データ転送のどこかで取りこぼしている」と疑いたくなります。私もそう考えて、調査の方向をまるごと間違えました。あとから振り返れば、データは1件も欠けていませんでした。犯人はタイムゾーンです。
この記事は、BigQueryで月次集計した数字が元ツールと合わないときに、まず疑うべき一点と、その直し方を書きます。SQLを1箇所直すだけで解決することがほとんどです。同じ「数字が合わない」で消耗する人を1人でも減らせればと思って、自分の誤診の経緯ごと残します。
結論:犯人はタイムゾーン。DATEにタイムゾーンを渡すだけ
先に直し方を出します。月境界の集計でズレるのは、たいていUTCとJSTの時差が原因です。
業務ツール側の日付はJST(日本標準時)で表示されているのに、BigQueryに入るときはUTC(協定世界時、日本より9時間遅い)のTIMESTAMP(=日時を世界標準時で持つ型)になっています。この時差を無視して月で割ると、月初・月末のレコードが隣の月に滑り込みます。
-- NG: UTCのまま月割り。JSTの月初レコードが前月に落ちる
SELECT
FORMAT_DATE('%Y-%m', DATE(created_at)) AS ym,
COUNT(*) AS cnt
FROM events
GROUP BY ym;
-- OK: DATE() にタイムゾーンを渡してJSTに直してから月割り
SELECT
FORMAT_DATE('%Y-%m', DATE(created_at, 'Asia/Tokyo')) AS ym,
COUNT(*) AS cnt
FROM events
GROUP BY ym;
違いは DATE(created_at) を DATE(created_at, 'Asia/Tokyo') にしただけ。DATE 関数はTIMESTAMPを日付に丸めるとき、第2引数にタイムゾーンを取れます。これを省くとUTC基準で丸まり、JSTで「月初の0時」だったレコードが前月の最終日に化けます。
この1文字レベルの差で、月次の件数が数件ずれます。少額の経費精算が毎月微妙に合わない、くらいの地味さで、しかも数字としては「それっぽく」出てしまうのが厄介なところです。
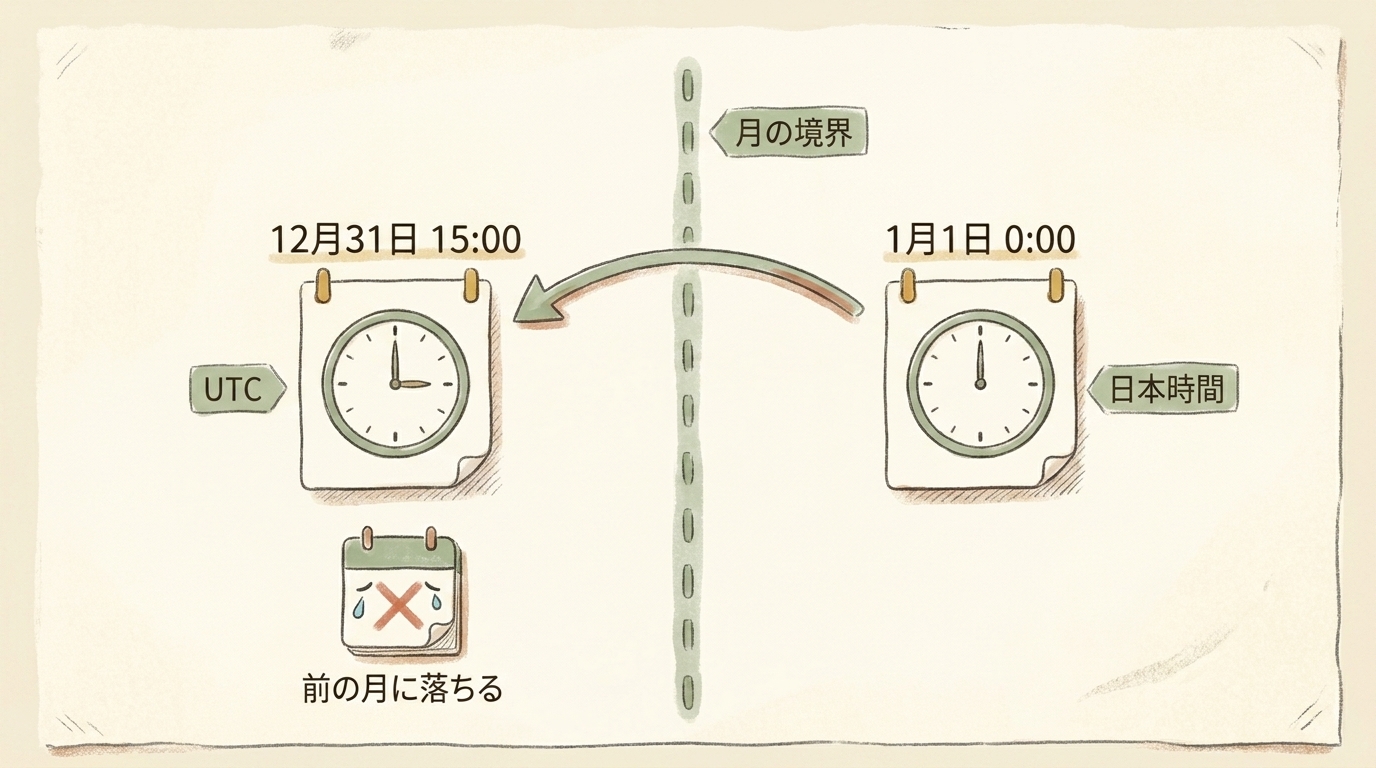
なぜズレるのか:月の境界でUTCとJSTが食い違う
具体的な日時で見ると腑に落ちます。
JSTの「2025年1月1日 0:00」は、9時間戻したUTCでは「2024年12月31日 15:00」です。この1件は、JSTの感覚では1月のレコードですが、UTC基準で DATE() を取ると 2024-12-31 になります。月で割れば12月にカウントされる。
レコードの実際のタイミング(JST) | UTCに直すと |
|
|
|---|---|---|---|
2025-01-01 0:00 | 2024-12-31 15:00 | 2024-12-31(12月扱い) | 2025-01-01(1月扱い) |
2025-01-31 23:30 | 2025-01-31 14:30 | 2025-01-31(1月扱い) | 2025-01-31(1月扱い) |
2025-02-01 6:00 | 2025-01-31 21:00 | 2025-01-31(1月扱い) | 2025-02-01(2月扱い) |
ズレるのは「JSTの0:00〜9:00に発生したレコード」だけです。日中のレコードは影響を受けません。だから全件が大きくずれるのではなく、月の境目あたりの早朝レコードが前後の月にこぼれて、合計が数件単位で食い違う。
毎月のレコード数が多いほど、月初・月末の早朝に当たるレコードも一定数あります。月あたり数件から十数件、というのが私が見たズレの幅でした。これが「転送の取りこぼし」と区別しづらい量だったのが、誤診を招いた直接の原因です。
実話:「同期欠損」と報告して、後で全面訂正した

ある案件の問い合わせ管理ツールのデータを、BigQueryに集約して月次で集計していました。元ツールのダッシュボードと突き合わせると、月ごとに数件から十数件、数字が合いません。多い月もあれば少ない月もある。
このとき私は、データ連携パイプラインのどこかでレコードを取りこぼしている、つまり「同期欠損が起きている」と判断しました。そう報告もしました。転送処理のログを追い、再実行を検討し、欠損レコードを探す前提で半日ほど調査の段取りを組みました。
ところが、欠けているはずのレコードがどうしても見つからない。BQ側の総件数と元ツールの総件数を年単位で足し合わせると、ぴったり一致するのです。「欠損しているのに総数が合う」という矛盾で、ようやく前提を疑いました。
月の境界に当たる早朝のレコードを1件ずつ見ていくと、JSTで1月1日のレコードがBQの集計では12月に入っていました。欠損ではなく、月の振り分けがUTC基準でずれていただけ。データは最初から1件も欠けていなかった。
集計SQLを DATE(日付, 'Asia/Tokyo') に直したら、12ヶ月すべてで元ツールと件数が完全一致しました。報告は訂正しました。「欠損」という言葉で原因を1つに決めつけ、調査の方向をまるごと間違えたのが反省点です。
この「直近の数字が変だから何かが壊れている」という早合点は、集計の世界でよく起きます。直近月の成約率だけ妙に低い現象を「異常」ではなく集計の仕様として扱う話は、BigQueryでコホート成約率を出すときに直近月を正しく扱う実装で別途書きました。数字の異常をすぐ「障害」に結びつけない、という点で根っこは同じです。
検証手順:合わない数字を「欠損」と決める前に

数字が合わないとき、いきなり転送ログを掘る前に、次の順で潰すと早いです。タイムゾーンは最初に揃えてしまうのが鉄則です。
手順1:総件数を期間まるごとで突き合わせる
まず細かい月別を見ずに、対象期間の総件数をBQと元ツールで比べます。
SELECT COUNT(*) AS total
FROM events
WHERE created_at >= TIMESTAMP('2024-12-31 15:00:00') -- JST 2025-01-01 0:00
AND created_at < TIMESTAMP('2025-12-31 15:00:00'); -- JST 2026-01-01 0:00
ここで総数が一致するなら、欠損ではありません。月の振り分けがずれているだけです。私の場合、この一致こそが「欠損ではない」と気づく決め手でした。総数が合わない場合に初めて、転送の取りこぼしを疑います。
手順2:タイムゾーンを揃えて月別を出し直す
総数が合ったら、集計SQLの DATE() にタイムゾーンを足して月別を出し直します。
SELECT
FORMAT_DATE('%Y-%m', DATE(created_at, 'Asia/Tokyo')) AS ym,
COUNT(*) AS cnt
FROM events
GROUP BY ym
ORDER BY ym;
これで元ツールと月別件数が揃うはずです。揃えば原因はタイムゾーンで確定。揃わなければ別の原因(フィルタ条件の差、重複、定義のズレ)に進みます。
手順3:境界のレコードを実物で確認する
念のため、月初の早朝に発生したレコードを実際に見ます。
SELECT
created_at,
DATE(created_at) AS date_utc,
DATE(created_at, 'Asia/Tokyo') AS date_jst
FROM events
WHERE DATE(created_at) != DATE(created_at, 'Asia/Tokyo')
ORDER BY created_at
LIMIT 50;
date_utc と date_jst が食い違う行が、月をまたいでこぼれていたレコードです。この行数が、月別集計のズレ件数とおおむね一致します。ここまで見れば「欠損ではなくタイムゾーン」と自信を持って言い切れます。
数字が合わない時に疑う順番(持ち帰り用チェックリスト)
集計値が元ツールと合わないとき、上から順に潰してください。安いものから先に、が原則です。
- タイムゾーンを揃えたか:日付列がUTCのTIMESTAMPで、集計はJST基準か。
DATE(x, 'Asia/Tokyo')を入れたか。月境界のズレはまずこれ - 総件数は合うか:期間まるごとの総数を突合。合うなら欠損ではなく振り分けの問題
- 集計の対象期間がズレていないか:「次より後/前」のような境界を含まない条件で、月初・月末の1日を落としていないか
- フィルタ条件が両者で同じか:元ツールのダッシュボードが裏で「特定ステータスのみ」などの条件を持っていないか
- 重複レコードがないか:転送のリトライで同じレコードが二重に入っていないか
- ここまで全部クリアして初めて「欠損」を疑う:転送ログ・再実行の調査はこの順番の最後
「数字が合わない=データが欠けている」と最初に飛びつかないこと。私の半日は、この順番を守っていれば最初の10分で終わっていました。
この対処が向くケース・向かないケース
DATE(x, 'Asia/Tokyo') で揃えるのは、日付列がUTCのTIMESTAMPで入っている前提の対処です。前提が違うと効きません。
向くケース:
- 業務ツールやSaaS由来のデータを、TIMESTAMPでBigQueryに取り込んでいる
- 元ツール側の表示はJST、BQ側はUTCで、月次・日次の件数が境界でずれる
向かないケース:
- 日付列がすでに
DATE型(時刻もタイムゾーンも持たない)で入っている場合。このときはタイムゾーン変換の余地がなく、ズレの原因は別(取り込み時点で日付がどう丸められたか) - 元ツール自体がUTC基準で集計している場合。揃えるべき基準がそもそもUTCなら、JSTに直すと逆にズレる
要は「BQと元ツールで、どのタイムゾーンを正とするか」を最初に決めることです。多くの国内業務では正はJSTですが、海外拠点をまたぐデータだと話が変わります。集計の基準タイムゾーンを設計時に1つ決めておく、これが一番効きます。
まとめ:差異調査の前に、タイムゾーンを揃える
BigQueryの月次集計が元ツールと数件ずつ合わないとき、最初に疑うのはタイムゾーンです。
- 日付がUTCのTIMESTAMPで入っているなら、
DATE(x, 'Asia/Tokyo')でJSTに直してから月割りする - 総件数を期間まるごとで突合する。合うなら欠損ではなく月の振り分けのズレ
- 「数字が合わない=欠損」と飛びつかない。安い原因(タイムゾーン・境界条件・フィルタ)から順に潰す
私はこの順番を踏まず「同期欠損」と決めつけて、調査をまるごと空振りさせました。データは1件も欠けていなかった。差異調査は、まず土俵をそろえることから始める。それだけで多くの「合わない」は片付きます。
データの数字が合わなくてお困りなら
「ダッシュボードとBigQueryの数字が合わない」「どこかで欠損している気がするが原因が分からない」。こうした集計の食い違いは、タイムゾーンや境界条件のような地味な原因がほとんどで、調査の順番を間違えると何日も溶けます。
f2t.jpでは、複数ツール間のデータ突合や、BigQueryでの集計設計・基盤構築をお手伝いしています。まずは「どのツールとどのツールの数字が合わないのか・正とすべき基準は何か・本当に欠損なのか」を一緒に切り分けるところから始められます。お問い合わせフォームから、合わない数字の状況をお寄せください。
この記事のテーマに合うサービス:業務フロー自動化
スプレッドシート・メール・Slackの往復を、自動化で終わらせる



