BigQuery Authorized ViewでPIIを隠して外部共有する設計。生データを渡さない4つの仕組み

BigQuery Authorized ViewでPIIを隠して外部共有する設計。生データを渡さない4つの仕組み
代理店や外部パートナーに、BigQuery(=Googleの大規模データ分析基盤)に貯めた数値を共有したい。広告の成果やコンバージョンの傾向を、相手にも見ながら一緒に動いてほしい。けれど顧客の氏名・電話番号・メールアドレスは、相手の画面に一切出したくない。
この「集計は見せたいが個人情報は見せたくない」という要件は、口で言うほど単純ではありません。BigQueryの権限の仕組みを正しく押さえずに設定すると、見せたつもりのないデータまで相手に見えてしまう事故が起きます。守るべきは安さではなく、生データへのアクセス権を不用意に外部へ渡さないこと。設計責任がそのまま漏洩リスクに直結するテーマになる。
この記事では、外部パートナーにPII(=個人を特定できる情報。氏名・電話・メールなど)を隠したまま集計だけを共有する設計を扱います。BigQueryのAuthorized View(=指定したビューにだけ生テーブルの閲覧を許可する仕組み)を連鎖させる方式を中心に、仕組み・実装の流れ・各方式の比較・自社か外注かの判断軸まで、稟議や発注の判断に使える材料を渡します。
データ基盤そのものをどう組むかは中小企業がBigQueryでGA4データ基盤を作るときの実務知識で扱っているので、基盤側から考えたい人はそちらも参照してほしい。本記事はその基盤を「外部に開く」段で何に気をつけるかに絞る。
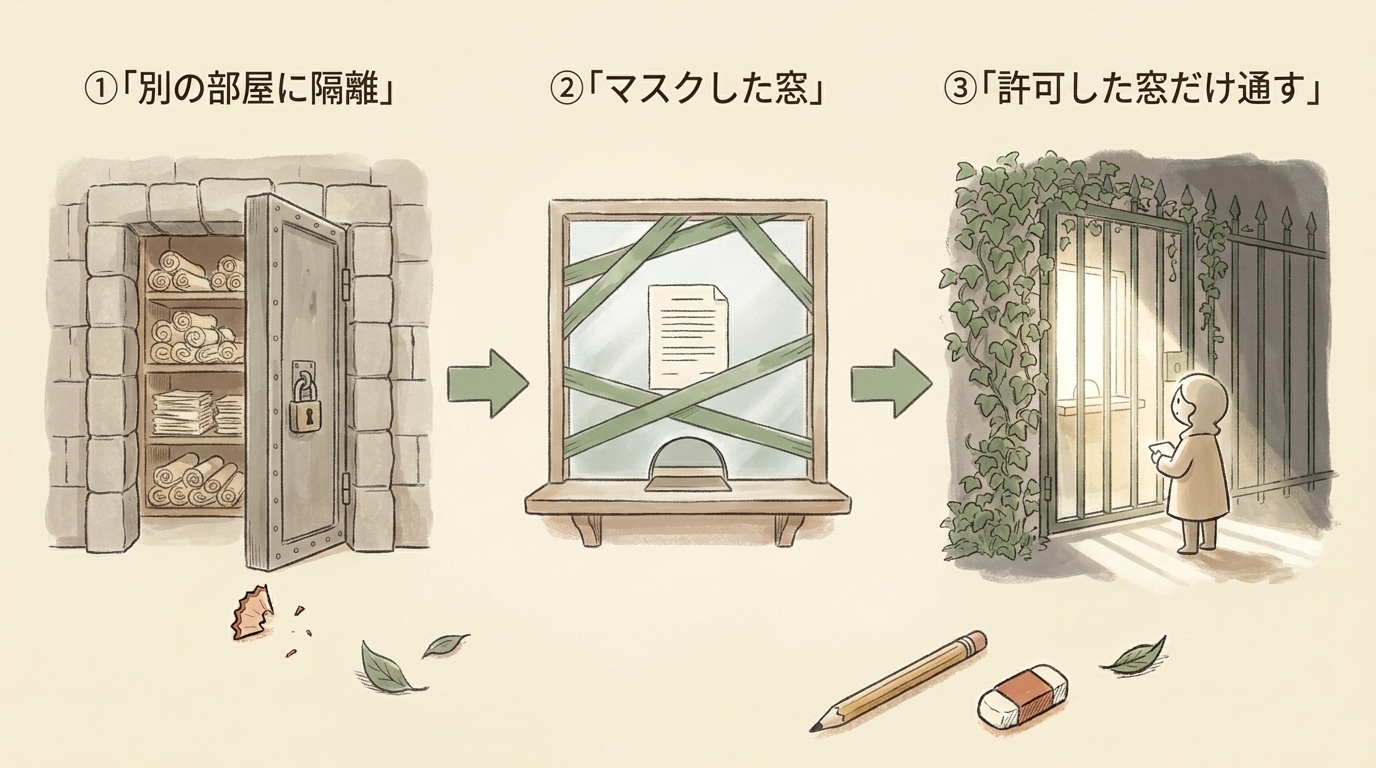
結論:別データセット隔離・マスクビュー・Authorized View連鎖の3点で組む
外部共有でPIIを守る設計は、次の3つを組み合わせるだけで成立します。
# | 仕組み | やること |
|---|---|---|
① 隔離 | 外部共有専用のデータセットを作る | 生データを置く場所と、外部に見せる場所を物理的に分ける |
② マスク | 専用データセットにマスク済みビューだけを置く | メールはドメインだけ、電話は下4桁だけ。氏名・本文は載せない |
③ 連鎖 | マスクビューに生テーブルの閲覧をAuthorized Viewで許可する | 外部者本人ではなく「ビュー経由でだけ読める」状態を作る |
最大の落とし穴を先に共有します。
データセットに閲覧権限(READER)を付与すると、そのデータセットの生テーブルが全部見えてしまう
「分析用のビューだけ見せたいから」とREADERを付けたつもりが、ビューが裏で参照している生テーブル(PII入り)まで丸見えになる。これでは個人情報保護になりません。だから外部者には生データセットを一切触らせず、専用データセットのマスクビュー経由でしか読めない構造にする。これが設計の核になる。
なぜ「ビューだけ見せる」が成立しないのか
BigQueryの権限は、原則としてデータセット単位で付きます。あるデータセットの閲覧権を相手に渡すと、その中のテーブルもビューも区別なく見える。「このビューだけ」という細かい指定が、素のままではできない仕組みになっています。
ここで効くのがAuthorized Viewです。Authorized Viewは「このビューには、生テーブルを読む権限を与えてよい」と生データ側に登録する仕組み。登録すると、ビューを実行した人が生テーブルへの直接権限を持っていなくても、ビュー経由でなら集計結果を取得できる。外部者本人には生テーブルの閲覧権を一切渡さず、マスクビューにだけ「裏で読んでよい」という権限を持たせる。これでPIIを通さずに集計だけを外へ出せる。
全体像はこうなります。実際のデータセット名は伏せ、役割で表記します。
外部パートナー(partner@example.com)
│ 閲覧権限は「外部共有専用データセット」だけに付与
▼
外部共有専用データセット(マスク済みビューだけを置く場所)
├─ マスクビューA(email/phone/氏名をマスク・除外)
├─ マスクビューB
│ Authorized Viewで生データ側の閲覧を許可
▼
生データセット(外部者は一切アクセス不可)
├─ 中間ビュー(複数の源泉を束ねる)
│ Authorized Viewで源泉側の閲覧を許可
▼
源泉データセット(フォーム回答・通話ログなど)
└─ 生テーブル(氏名・電話・本文などの生PII)
外部者がアクセスできるのは専用データセットだけ。そこにあるのはマスク済みビューだけ。ビューは裏で生テーブルを読みますが、それはAuthorized Viewの仕組みで「ビュー経由なら読める」状態を作っているからです。外部者自身は生テーブルへの直接権限を持たない。ここが構造の肝になる。
実装の流れ:5つのステップ
以下は実際に組むときの手順です。具体的なコマンドやSQLの全文は載せず、各ステップで「何をする操作か」を言葉で示します。BigQueryの操作に慣れた人なら、この流れがそのまま設計図になるはずです。
ステップ1:外部者に誤って付いている生データセットの閲覧権を外す
すでに外部者へ生データセットの閲覧権を付けてしまっている場合、まずそれを剥がします。これを残したまま専用データセットを作っても、生データが見える経路が残るので意味がありません。
ここで一つ環境依存のつまずきがある。権限を付け外しする標準コマンドが、利用しているプロジェクトの制限(allowlist)で使えないことがある。その場合は、データセットのアクセス設定を一度JSONとして書き出し、該当する外部者の閲覧権の記述を取り除いてから、編集したJSONで上書きする方式に切り替えます。コマンド一発で済まないケースがあると知っておくと、手が止まらずに済む。
ステップ2:外部共有専用のデータセットを作る
マスク済みビューだけを置くための、外部共有専用データセットを新規に作成します。ここに生テーブルは一切置かない。役割を「外部に見せてよいものだけの棚」と決めておくのが、後の運用ミスを防ぎます。
ステップ3:PIIをマスクしたビューを専用データセットに作る
生データを参照しつつ、PIIを伏せたビューを作ります。マスクの方針は「集計には使えるが、個人は特定できない」レベルにそろえる。列ごとに扱いを分けるのがポイントになる。
列の種類 | 扱い | 理由 |
|---|---|---|
メールアドレス | ドメインだけ残す( | 個人は特定できないが、ドメイン分布の集計には使える |
電話番号 | 下4桁だけ残す( | 識別はできないが、重複判定などには役立つ場面がある |
氏名・問い合わせ本文 | ビューに載せない(完全除外) | マスクしても文脈から個人が復元される恐れがある |
地域 | 都道府県レベルに丸める | 詳細な住所は特定材料になるため粒度を落とす |
広告ID・コンバージョン日・成約フラグなど | そのまま残す | 分析に必要で、個人特定には直結しない |
マスク処理を書くとき、空のメールや「@」を含まない値などの想定外データで処理が落ちると、ビュー全体がエラーになります。条件分岐で異常値を先にはじく作りにしておくのが安全になる。
ステップ4:Authorized Viewを連鎖の全階層で登録する(最大のハマりどころ)
マスクビューが生テーブルを読むには、生データ側に「このビューは承認済み」と登録する必要があります。ここが設計で一番つまずく場所です。
問題は、ビューが多段になっているときに起こります。マスクビューが中間ビューを参照し、中間ビューが源泉の生テーブルを参照する、という連鎖構造のとき、各層すべてで承認登録が要る。
マスクビュー(専用データセット)
└─ 中間ビュー(生データセット)を参照
└─ 源泉の生テーブル(フォーム・通話ログ)を参照
この構造なら、登録が必要な箇所は次のとおりになります。
- 生データセットに、専用データセットのマスクビューを承認登録する
- 源泉データセットに、生データセットの中間ビューを承認登録する
どこか1層でも登録が抜けると、ビューを実行したときに権限エラーで落ちます。多段ビューでつまずく人の大半が、この中間層の登録漏れです。連鎖のリンクを全部つないだか、上から下まで確認する。
ステップ5:外部者に閲覧権を付与して、マスクが効いているか目視する
最後に、外部共有専用データセットにだけ閲覧権を付与します。生データセットには付けない。
付与したら、マスクビューからサンプルを取り出し、メールが***@gmail.comの形になっているか、電話が下4桁だけか、氏名や本文がそもそも出てこないかを自分の目で確認します。設定が正しくても、確認を飛ばすと「実は1列だけ素のまま出ていた」を見逃す。最後の目視は省かない。
設計でつまずく4つの落とし穴
実装ステップの中でも特にハマりやすい点を、まとめて挙げておきます。外注先に確認するときのチェック項目としても使えます。
落とし穴1:Authorized Viewは連鎖の各層で必要
ビューAがビューBを参照し、ビューBが生テーブルCを参照する構造で、ビューAの利用者がBやCへの直接権限を持たないとき、Bのある場所でAを承認し、Cのある場所でBを承認する。どちらか片方だけでは動きません。連鎖のリンクを全部登録する。
落とし穴2:権限を付け外しする標準コマンドが使えない環境がある
権限変更の標準コマンドが「この機能はallowlistが必要」というエラーで弾かれる環境があります。そのときは前述のとおり、アクセス設定をJSONで書き出して直接編集する方式に切り替える。
落とし穴3:プロジェクト全体に効く実行権・メタ情報閲覧権は残す
「READERを外す」のはデータセット単位の話です。プロジェクト全体に効くクエリ実行権とメタ情報の閲覧権まで剥がすと、ビューの実行そのものが走らなくなります。剥がすのはデータセット単位の閲覧権だけ。ここを混同して全部外すと、外部者は何も実行できなくなる。
落とし穴4:マスク処理の異常値対策
「@」がないメールや空文字といったエッジケースで文字列処理が落ちると、ビュー全体が止まります。異常値を条件分岐で先にはじく作りにしておく。
共有前と共有後で何が変わるか

この設計を入れる前と後で、外部共有のリスクと運用がどう変わるかを並べます。
Before(データセット閲覧権をそのまま付与) | After(隔離+マスク+Authorized View) | |
|---|---|---|
外部者に見える範囲 | 生テーブルのPIIまで丸見え | マスク済みの集計列だけ |
漏洩リスク | 氏名・電話・本文が外部に渡る | 個人を特定できる情報は通らない |
共有する単位 | データセットまるごと | 見せてよいビューだけを選んで開く |
設定ミスの影響 | 一度の付与で全PIIが流出 | 専用データセットに隔離され被害が閉じる |
運用 | 「このテーブルは見せていいか」を都度悩む | 専用データセットに置くものを管理するだけ |
差は「何が見えるか」より「事故ったとき被害がどこで止まるか」に出ます。生データセットへの経路を断っておけば、専用データセット側で多少のミスがあっても、生PIIまでは届かない。被害範囲を構造で閉じておくのが、この設計の本当の価値になる。
どの方式で外部にデータを渡すか:4つの比較
そもそもBigQueryのAuthorized Viewを使わなくても、データを外部に渡す手段は他にもあります。代表的な4方式を、漏洩リスクと運用負荷の2軸で並べます。
方式 | 漏洩リスク | 運用負荷 | 向くケース |
|---|---|---|---|
CSVを手で書き出して渡す | 高い。一度渡したファイルは追跡不能、コピーも止められない | 都度の書き出し・マスク作業が毎回発生 | 単発・一度きりの共有 |
スプレッドシートで共有 | 中。閲覧権限の付け間違い・転送で広がりやすい | 元データの更新を手で反映する手間 | 数値が少なく、更新頻度も低い |
BigQueryを直接共有(データセット閲覧権) | 高い。生テーブルのPIIまで見える | 設定は楽だが、見せたくない列も渡る | 社内・信頼できる相手で、PIIが無い場合のみ |
マスクビューをAuthorized Viewで共有(本記事の方式) | 低い。個人を特定できる情報が通らない | 初期設計に手間。組めば後は自動で最新が反映 | 継続的に集計を共有したい外部パートナー |
CSVやスプレッドシートは「手軽さ」で選ばれがちですが、一度外に出たファイルは取り戻せず、マスクの手作業に漏れが混じれば即PII流出になる。BigQueryを直接共有する方式は設定こそ楽でも、生テーブルが見えてしまう。継続的に外部と数値を共有し続けるなら、初期に設計コストを払ってでもマスクビュー+Authorized Viewにするのが、長い目で見て最も漏洩リスクが低い。安さや手軽さで方式を決めると、後から取り返しのつかない流出を招きます。リスクを主役に置いて選ぶ。
自社でやるか、外注するか
「BigQueryを触れる人が社内にいるなら自社で」と即決する前に、次の3点で見てください。
判断軸 | 自社向き | 外注向き |
|---|---|---|
Authorized Viewの連鎖を理解している人がいるか | いる(多段登録まで把握) | いない/READERとの違いが曖昧 |
外部に渡すデータにPIIが含まれるか | 含まない/マスク設計を自前で詰められる | 含む(設計を誤ると漏洩に直結) |
共有先・列構成が今後も変わるか | 自分で改修し続けられる | 一度組んで安定運用したい |
特に2番目が重い。外部に渡すデータにPIIが含まれていて、社内にマスク設計とAuthorized View連鎖を正しく組める人がいないなら、迷わず外注したほうがいい。ここを「たぶん大丈夫」で進めると、付与の一手間違いで顧客の個人情報が外部に渡る。設定の難しさより、ミスったときの被害の大きさで判断すべき領域になる。
こんなケースには向かない
この設計を無理に入れないほうがいい場面も正直に挙げます。
- 共有が単発・一度きり:継続しないなら、その場でマスクしたCSVを1回渡すほうが速い場面もある
- 渡すデータにそもそもPIIが無い:マスクが不要なら、設計を簡素にできる。ただし「無いと思っていた列にPIIが混ざる」事故は多いので、共有前に全列を点検する
- 外部に渡す数値がごく少数:列も行も少ないなら、スプレッドシートの権限管理で足りることもある
継続的に・ある程度の量の集計を・PIIを含むデータから外部へ共有し続ける。この条件がそろうほど、Authorized View連鎖の設計コストが報われます。
共有設計を始める前のチェックリスト

着手前に次を整理しておくと、設計がぶれません。
- 誰に共有するか(代理店/業務委託先/グループ会社)→ 信頼度と権限範囲が変わる
- 渡すデータにPIIが含まれるか(含むなら、どの列をマスク・除外するか列単位で決める)
- ビューは多段か(多段なら、各層でAuthorized View登録が要ると見積もる)
- 生データセットへの経路を完全に断てるか(専用データセットだけに閲覧権を付けられるか)
- 付与後に目視確認する担当を決めたか(マスクが効いているかを誰が最終確認するか)
- 列構成が変わったとき誰が直すか(共有先の要望で列が増減したときの保守責任)
この6つが決まれば、あとは前述の5ステップを組むだけになる。
まとめ:外部共有は「生テーブルを見せない」を構造で担保する
BigQueryで外部パートナーにデータを安全に共有する設計は、次の4点に集約されます。
- 外部共有専用のデータセットを作り、そこにマスクビューだけを置く
- 外部者には専用データセットだけに閲覧権を付与し、生データセットには一切触れさせない
- Authorized Viewを連鎖の全階層で登録する(中間層の登録漏れが最大の事故源)
- 氏名・本文は完全除外、メール・電話はマスクして集計可能性だけ残す
「ビューだけ共有」のつもりでデータセット閲覧権を付けると、生PIIが丸見えになる。この一手の取り違えが、そのまま顧客情報の流出になります。守るべきは「外部者に生テーブルを一切見せない」という一点。それをAuthorized Viewの仕組みで構造的に担保することが、コンプライアンスを保ちながらデータ活用を前に進める最短ルートになる。
外部共有を見据えたデータ基盤のセキュリティ設計でお困りなら
「代理店にも数値を見せて一緒に動きたい。でも顧客の個人情報は絶対に外へ出したくない」。この両立は、権限設計を最初に正しく組めるかで決まります。後から付け替えるより、共有相手・PIIの有無・ビューの段数・保守責任を最初に整理しておくほうが、事故も手戻りもずっと少なくなる。
f2t.jpでは、BigQueryのデータ基盤設計から、PII保護を前提にした外部共有の権限設計まで一貫してお手伝いしています。まずは「誰に・どの数値を・どう守りながら共有したいか」を一緒に棚卸しするところから始められます。お問い合わせフォームから、自社の外部データ共有でお困りの点をご相談ください。
この記事のテーマに合うサービス:業務フロー自動化
スプレッドシート・メール・Slackの往復を、自動化で終わらせる



