BigQuery SQLでハマる5つの落とし穴:JOIN重複・相関サブクエリ・日本語カラム名ほか

BigQuery SQLでハマる5つの落とし穴:JOIN重複・相関サブクエリ・日本語カラム名ほか
BigQueryでデータ分析をしていると、エラーは出ないのに数字がおかしい、他のDBでは動くSQLが動かない、といった落とし穴に何度もハマります。知っていれば一瞬で回避できるのに、知らないと原因究明に何時間も溶かすタイプのものです。
この記事では、実際の分析業務で踏んだBigQuery特有の5つの落とし穴と、その回避策をまとめます。同じところで時間を溶かさないための実務メモとして使ってください。
結論:頻出する5つの落とし穴
まず一覧で出します。
- JOINで件数が水増しされる(1対多マッチで行が膨張)
- 相関サブクエリのクロステーブル参照ができない(他DBでは動くのに)
- テーブルごとに同じ意味のカラム名が違う(phone / phone_digits / 電話番号)
- bq CLIが日本語カラム名で落ちる(Pythonクライアントで回避)
- 運用変更の履歴が通常クエリでは取れない(専用リソースが必要なケース)
詳細に入る前に、罠と対策の早見表を置いておきます。手元のクエリでどれに当てはまるか、まずここで当たりをつけてください。
# | 落とし穴 | 症状 | 対策 |
|---|---|---|---|
1 | JOINで件数が水増し | エラーなしで件数が膨らむ | JOIN前後でCOUNT(*)を検算。COUNT(DISTINCT) / EXISTS / MAX(CASE) |
2 | 相関サブクエリ非対応 |
| LEFT JOIN + GROUP BY + 集約に書き換え |
3 | カラム名の不統一 | 「あるはず」のカラムが無くてエラー |
|
4 | bq CLIの日本語問題 |
| Python BigQueryクライアント経由で実行 |
5 | 変更履歴が取れない | 現状値しか返らない |
|
順番に見ていきます。
落とし穴1: JOINで件数が水増しされる(最頻出)
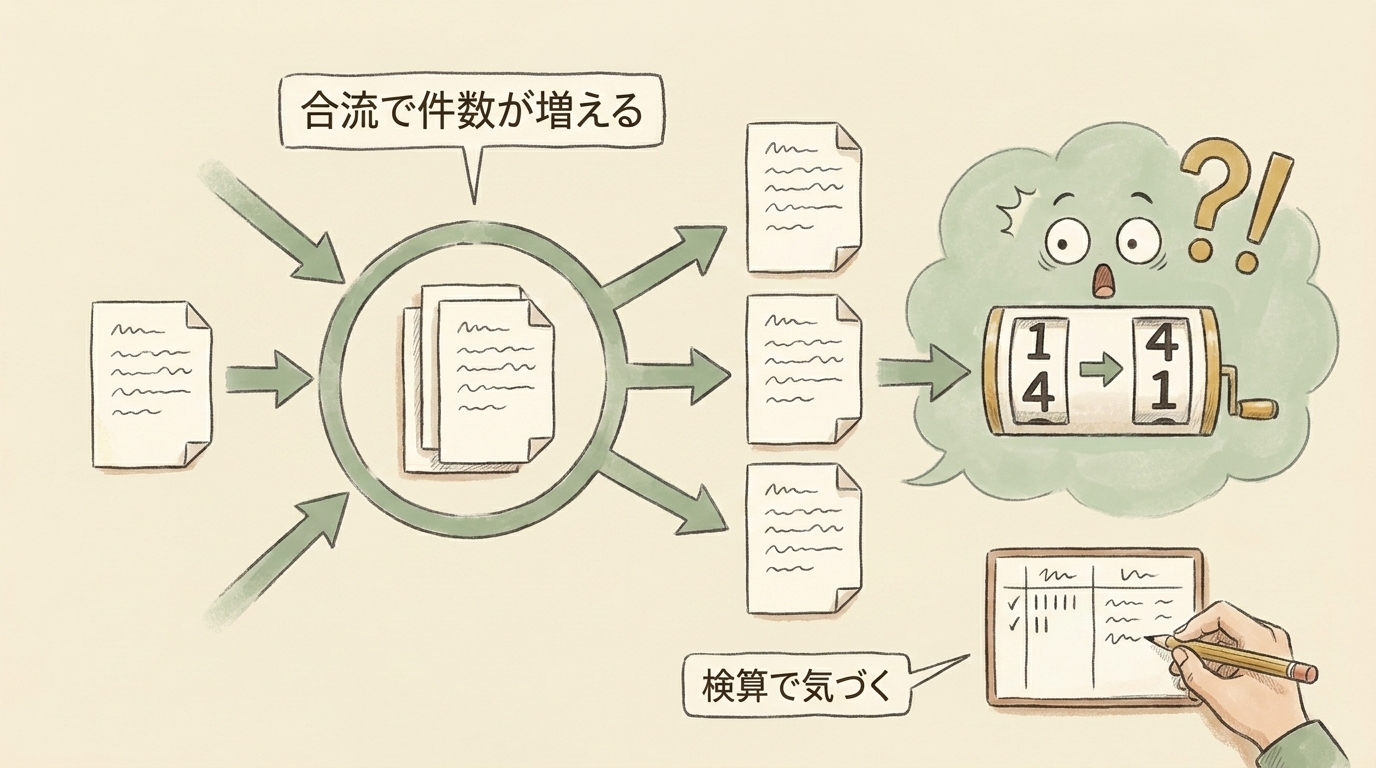
一番よく踏むのがこれです。LEFT JOINで2つのテーブルを結合したら、COUNT(*) の件数が膨らみます。
-- ❌ 重複が発生する
SELECT COUNT(*) AS cnt
FROM orders o
LEFT JOIN order_items i USING (order_id)
WHERE i.order_id IS NOT NULL
1つの注文(order)に複数の明細(item)が紐づく場合、結合すると行が「注文数 × 明細数」に膨らみます。500件の注文が700件にカウントされる、といった事故になりがちです。エラーが出ないので、報告して初めて気づくこともあります。
回避策:用途に応じて3パターン
-- ✅ 対策1: COUNT(DISTINCT) で重複排除
SELECT COUNT(DISTINCT o.order_id) AS cnt
FROM orders o
LEFT JOIN order_items i USING (order_id)
WHERE i.order_id IS NOT NULL
-- ✅ 対策2: EXISTSで結合せず判定
SELECT COUNT(*) AS cnt
FROM orders o
WHERE EXISTS (
SELECT 1 FROM order_items i WHERE i.order_id = o.order_id
)
-- ✅ 対策3: MAX(CASE WHEN) で集約後に判定
SELECT
o.order_id,
MAX(CASE WHEN i.order_id IS NOT NULL THEN 1 ELSE 0 END) AS has_item
FROM orders o
LEFT JOIN order_items i USING (order_id)
GROUP BY o.order_id
鉄則は、JOIN前後で COUNT(*) を比較すること。行数が変わっていたら重複を疑います。10%以上ずれたら、書き込む前に必ず検算してください。これを習慣にするだけで、誤った数字を報告する事故はほぼ防げます。
落とし穴2: 相関サブクエリのクロステーブル参照ができない
他のDB(MySQL等)では普通に動く相関サブクエリ(=外側のテーブルの値を1行ずつ参照しながら回るサブクエリ)が、BigQueryでは弾かれることがあります。
-- ❌ BigQueryではエラー
SELECT
o.order_id,
(SELECT MAX(p.amount) FROM payments p WHERE p.order_id = o.order_id) AS amount
FROM orders o
エラーメッセージはこうなります。
Correlated subqueries that reference other tables are not supported
unless they can be de-correlated, such as by transforming them into
an efficient JOIN.
BigQueryは、外部テーブルを参照する相関サブクエリを限定的にしかサポートしません。
回避策:LEFT JOIN + 集約に書き換える
-- ✅ LEFT JOIN + MAX で書き換える
SELECT
o.order_id,
MAX(p.amount) AS amount
FROM orders o
LEFT JOIN payments p USING (order_id)
GROUP BY o.order_id
相関サブクエリは、ほとんどの場合「JOIN + GROUP BY + 集約関数」に書き換えられます。BigQueryでは最初からこの形で書くのが安全でした。
落とし穴3: テーブルごとにカラム名が違う
複数のテーブルを扱っていると、同じ意味のデータなのにカラム名がバラバラ、という場面に出くわします。
テーブル | 電話番号のカラム名 | 形式 |
|---|---|---|
テーブルA |
| 数字のみ正規化済み |
テーブルB |
| 国際形式(+81...) |
テーブルC |
| フォーマット混在 |
テーブルD |
| 発信者番号 |
「テーブルBのSQLをコピペしてテーブルAに使ったら、phone カラムが無くてエラー」というのは頻発します。データ基盤が複数のソースを束ねているほど起きやすい。
回避策:結合前にスキーマを確認する
-- カラム一覧を事前確認
SELECT column_name
FROM `PROJECT.DATASET.INFORMATION_SCHEMA.COLUMNS`
WHERE table_name = 'your_table'
INFORMATION_SCHEMA.COLUMNS(=そのデータセットのテーブル定義を引けるシステムビュー)でカラム名を確認してから書きます。「存在するはず」という思い込みで書かず、現物のスキーマを見るのが確実です。
複数ソースをBigQueryに集約していくと、こうしたカラム名の揺れは必ず出てきます。データ基盤としての設計の考え方は、中小企業がBigQueryとGA4でデータ基盤を作る進め方で整理しています。
落とし穴4: bq CLIが日本語カラム名で落ちる

日本語のカラム名(部位 日付 等)を含むSQLを bq query コマンドに渡すと、Illegal input character で失敗することがあります。バックティックでクォートしても回避できないケースがありました。
回避策:Pythonクライアントを使う
from google.cloud import bigquery
client = bigquery.Client(project='your-project')
sql = """
SELECT
IFNULL(t.`部位`, '(NULL)') AS part,
COUNT(*) AS cnt
FROM `your-project.dataset.table` t
WHERE t.`日付` >= '2025-11-01'
GROUP BY 1
"""
rows = [dict(r) for r in client.query(sql).result()]
原因は、bq CLIのコマンドラインパーサーが日本語をうまく扱えないことにあります。Python BigQueryクライアント経由なら、日本語カラム名でも問題なく動きました。日本語カラムを含むデータを扱うなら、最初からPythonで書くのが楽です。
落とし穴5: 運用変更の履歴が通常クエリでは取れない
「いつ、誰が、何を変更したか」を後から追いたいことがあります。たとえば広告アカウントで、ある日、複数のキャンペーン設定が一斉に変わったのを追跡したい、というケース。
ところが、通常のリソース(現在の設定値)には履歴が残っておらず、現状値しか取れません。
回避策:変更履歴専用のリソースを使う
サービスによっては、変更履歴専用のリソースが用意されています。たとえば広告プラットフォームのデータ転送では change_event のようなリソースで、変更日時・実行者・変更前後の値が取れます。
SELECT
change_event.change_date_time,
change_event.user_email,
change_event.changed_fields,
change_event.old_resource,
change_event.new_resource
FROM change_event
WHERE change_event.change_date_time DURING LAST_30_DAYS
ORDER BY change_event.change_date_time DESC
「現状値しか取れない」と諦める前に、変更履歴を持つ専用リソースがないかを確認してください。設定変更のトラブルシュートでは、これがあるかないかで調査時間が桁違いに変わります。
アンチパターン3つ
アンチパターン1: JOIN後に件数を検算しない
JOINで件数が膨らんでも、エラーは出ません。JOIN前後で COUNT(*) を比較しないと、水増しされた数字をそのまま報告してしまいます。検算は習慣化が正解。
アンチパターン2: 他DBのSQLをそのまま持ち込む
相関サブクエリのように、他DBで動いてもBigQueryで動かない構文があります。BigQueryの作法(JOIN + 集約)で書き直しましょう。
アンチパターン3: カラム名を「あるはず」で書く
テーブルごとにカラム名は違います。INFORMATION_SCHEMA で確認してから書けば、存在しないカラムでのエラーを防げます。
まとめ:BigQueryには「BigQueryの作法」がある
BigQuery SQLの5つの落とし穴を整理すると、こうなります。
- JOINの重複 → JOIN前後で件数検算、COUNT(DISTINCT)/EXISTS/MAX(CASE)で対処
- 相関サブクエリ → LEFT JOIN + 集約に書き換える
- カラム名の不統一 → INFORMATION_SCHEMAで事前確認
- bq CLIの日本語問題 → Pythonクライアントを使う
- 変更履歴 → 専用リソース(change_event等)を探す
どれも「知っていれば一瞬、知らなければ数時間」の落とし穴です。とくにJOINの重複は、エラーが出ないまま誤った数字を報告してしまう怖いパターン。件数の検算を習慣にしておくと安心できます。
データ分析基盤の設計でお困りなら
BigQueryは強力ですが、独特の作法があり、集計の正確性を担保するには経験が要ります。「複数のデータソースを束ねたら数字が合わなくなった」「クエリのエラー潰しに時間が取られて、肝心の分析が進まない」という状況は、設計段階で多くを避けられます。
f2t.jpでは、BigQueryのデータ分析基盤の設計から、集計の正確性を担保する仕組みづくりまで一貫してお手伝いしています。お問い合わせフォームからお気軽にどうぞ。
この記事のテーマに合うサービス:業務フロー自動化
スプレッドシート・メール・Slackの往復を、自動化で終わらせる



