WordPress REST APIで記事の生データを取る方法。context=editで本当の中身を読む

WordPress REST APIで記事の生データを取る方法。context=editで本当の中身を読む
WordPressの記事を分析する、別サイトに移行する、同じトーンで新記事を書く。こういうタスクで、ついブラウザに表示されたHTMLを取得してしまう人は多いと思います。
ただ、それは落とし穴になります。ブラウザに表示されるHTMLはWordPressがレンダリングした後の最終形で、元の記事データとは別物です。これを「本文」と思い込むと、記事の本当の構造を見誤ります。
実話:ある記事分析タスクで、最初にHTMLを取得して「これが本文」と判断したことがありました。すると「内部リンクのスニペットも使っていますよね」と指摘される。本文の実体はショートコードを含む生データのほうに保存されていたわけです。
この記事では、WordPress記事の本当の中身を正確に取得する方法、REST APIの context=edit を解説します。
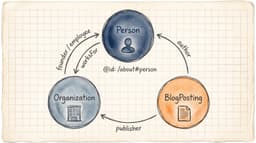
REST API=プログラムからWordPressを読み書きする窓口。ブラウザを介さずデータを直接やり取りできます。
結論:HTMLスクレイピングでなく、REST APIのcontext=editで生データを取る
要点を先に整理します。
- ブラウザのHTML(レンダリング後)を「本文」と誤認しない
- WordPressのREST APIで
context=editを指定すると、生のpost_contentが取れる - 生データにはショートコード・カスタムフィールド・タクソノミーが全部含まれる
- HTMLスクレイピングは「最終レンダリングの目視確認」だけに使う
context=edit=編集用の生データ(post_content)を返すモード。指定しないと表示用に整形済みのHTMLしか返ってきません。
記事の分析・移行・トーン再現では、最初の一手をHTMLスクレイピングにしないのが鉄則になります。

レンダリング後HTMLで見落とすもの

ブラウザで表示されるHTMLを取得すると、次のものを取りこぼします。
見落とすもの | 例 |
|---|---|
ショートコード |
|
カスタムフィールド | 監修者ID・フォーカスキーワードなど |
タクソノミー | カスタム投稿専用の分類 |
メタフィールド | SEOプラグインの設定 |
テーマの自動挿入部分 | CTAバナー・目次・関連記事 |
特にやっかいなのが、テーマが自動挿入する部分と本文の境界です。レンダリング後のHTMLでは、どこまでが記事データでどこからがテーマ由来か分かりません。
たとえば記事本文に [blogcard url="..."] というショートコードが1行あるだけでも、レンダリング後は「タイトル・サムネイル・抜粋付きのリッチなカード」に展開されます。HTMLを見ると立派なカードHTMLが本文の一部に見える。でも実際の記事データはショートコード1行です。
ここを誤認すると、記事を複製しようとしてリッチなHTMLをコピーし、複製先でショートコードが効かず崩れる、という事故になります。
REST APIで生データを取る
WordPressのREST APIで context=edit を指定すると、編集画面で見るのと同じ生のpost_contentが取れます。AIエージェントからWordPressを読み書きする場合も同じで、生データを起点にすると記事構造を正しく扱えます(Claude DesktopとMCPでWordPress運用を効率化する方法でも、操作の起点をデータ側に置く考え方を扱いました)。
Step 1: 認証情報を準備する
context=edit は認証が必要です。編集権限相当の情報を返すモードなので、アプリケーションパスワードやBasic認証を使います。
Step 2: カスタム投稿タイプを確認する
# 投稿タイプ一覧を取得
curl -s -u "$USER:$PASS" "https://example.com/wp-json/wp/v2/types"
通常の投稿(post)以外に、カスタム投稿タイプ(症例・お知らせ等)があるかを確認しておきます。
Step 3: 生コンテンツを取得する
# context=edit で生のpost_contentを取得
curl -s -u "$USER:$PASS" \
"https://example.com/wp-json/wp/v2/posts/123?context=edit"
レスポンスの content.raw に、ショートコードを含む生のHTMLが入っています。context=edit を付けないと content.rendered(レンダリング後)しか返りません。
{
"content": {
"raw": "記事の冒頭です。\n[blogcard url=\"...\"]\n続きの本文...",
"rendered": "<p>記事の冒頭です。</p><div class=\"blogcard\">...</div>..."
}
}
raw を見れば、「この記事はショートカードを使っている」「ここにカスタムフィールドの値が入る」といった本当の構造が読めます。
タスク別の正しい順序
CMS記事を扱うタスクの順序はこうなります。
- 対象ドメインのCMS種別を確認(WordPress / Headless CMS / Webflow等)
- REST APIのエンドポイントと認証を確認
- 認証情報を取得(1Passwordなどから)
- REST API
context=editで生データを取得。ショートコード・カスタムフィールド・タクソノミーが全部見える - HTMLスクレイピングは最終レンダリングの目視確認だけに使う
HTMLから入っていいのは、全くの初見ドメイン・認証情報がない・公開APIがない、このいずれかのときだけです。
アンチパターン3つ
アンチパターン1: レンダリング後HTMLを「本文」と誤認する
ブラウザに表示されるHTMLは、ショートコード展開・テーマ自動挿入を含んだ最終形でした。生のpost_contentとは別物です。
アンチパターン2: context=edit を付けずに取得する
context=edit なしだと content.rendered(レンダリング後)しか返りません。生データには context=edit が要ります。
アンチパターン3: いきなりHTMLスクレイピングから始める
記事の分析・移行・トーン再現では、最初の一手をREST APIにする。HTMLは目視確認用と割り切ります。
持ち帰り:取得方法の判断チェックリスト

どの方法で記事を取るか、迷ったときの判断軸です。上から順に確認してください。
確認項目 | YESなら | NOなら |
|---|---|---|
CMSはWordPressか | REST APIが使える。次へ | Headless CMS等のAPIを確認 |
編集権限の認証情報があるか |
| アプリパスワード等を発行する |
取りたいのは記事の構造・本文か |
| rendered/目視確認でも可 |
ショートコードやカスタムフィールドを使っているか | 必ず生データで確認 | rendered確認で足りる場合あり |
公開APIも認証もない初見ドメインか | HTMLスクレイピングから入る | REST APIを優先 |
このチェックリストを1枚持っておくと、移行や分析のたびに「まずHTMLを取って後で困る」を避けられます。
まとめ:記事の「本当の中身」は生データにある
WordPress記事を正確に扱う原則は4つです。
- ブラウザのHTML(レンダリング後)を本文と誤認しない
- REST APIの
context=editで生のpost_contentを取る - 生データにはショートコード・カスタムフィールド・タクソノミーが全部含まれる
- HTMLスクレイピングは最終レンダリングの目視確認だけ
記事の分析や移行で「なぜか複製先で崩れる」「トーンが再現できない」という問題の多くは、レンダリング後HTMLを元データと誤認したのが原因でした。生データを見るという最初の一手で、こうした事故は防げます。
CMS運用・コンテンツ移行でお困りなら
WordPressの記事を別サイトに移したら崩れた、AIに記事のトーンを学ばせたいが何を渡せばいいか分からない、社内に「データの本当の構造」を見られる人がいない。こうした状況に心当たりがあれば、表示されたHTMLではなくデータ側から扱うのが近道です。
f2t.jpでは、CMSの運用から記事の分析・移行・AIによるトーン再現まで一貫してお手伝いしています。お問い合わせフォームからお気軽にどうぞ。