Lark Baseで問い合わせ管理ダッシュボードを作る。属人化をなくす一元管理の導入判断

Lark Baseで問い合わせ管理ダッシュボードを作る。属人化をなくす一元管理の導入判断
「あの問い合わせ、誰が対応した?」。週に何度かこのやり取りが社内で起きていないでしょうか。
HPの問い合わせフォーム、広告用のLP、代表電話、最近はLINEからも。問い合わせの入口が増えるほど、情報はあちこちに散らばります。フォームの通知メールは担当者の受信箱、電話のメモは手帳かExcel、LINEは個人のスマホ。誰がどこまで対応したかが見えないまま、気づけば「3日前の問い合わせに誰も返していなかった」という事故が起きます。
しかも、対応のやり方が特定の人の頭の中にしかない。その人が休むと止まる、辞めると引き継げない。問い合わせは新規顧客の入口そのものなのに、その管理が一番属人化している会社は珍しくありません。Excelの一覧表で何とか回している会社も多いですが、複数人で同時に開けない、入力の表記がバラバラ、集計のたびに手作業、という別の問題を抱えがちです。
この記事では、複数チャネルに散らばった問い合わせを1か所に集めて、誰が・どこまで対応したかを全員が見られる状態にする仕組みを、ある医療系の案件で実際に組んだ経験をもとに紹介します。狙いは凝ったダッシュボードを作ることではなく、対応漏れと属人化をなくすことです。「自社でやるべきか・外注すべきか・いくらかかるか・どんな成果が出るか」を判断できるところまで書きます。
結論:管理テーブル1枚と自動振り分けの2部品で始める
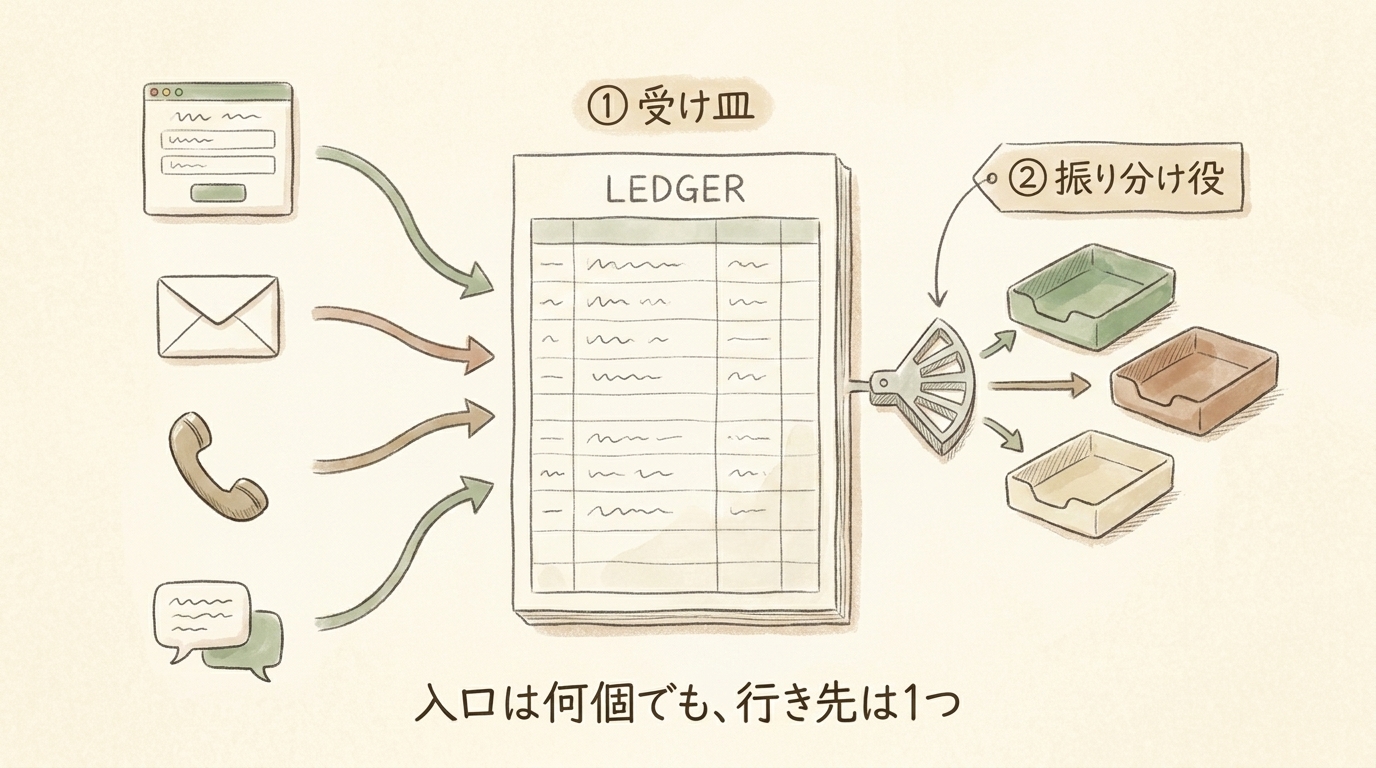
問い合わせの一元管理は、次の2つの部品から始めれば十分に効果が出ます。最初から豪華なダッシュボードを目指す必要はありません。
# | 部品 | やること | 使うもの(例) |
|---|---|---|---|
① 受け皿 | すべての問い合わせを1つの管理表に集める | 問い合わせ管理テーブル | Lark Base(=表計算とデータベースの中間のような業務アプリ基盤) |
② 振り分け役 | 「どのチャネルから来たか」を自動で分類する | 数式フィールド(=条件に応じて値を自動で埋める列) | Lark Base の数式フィールド |
この2つができれば、「全件が1か所に並ぶ」「どこから来た問い合わせかが一目で分かる」「対応ステータスを全員が見られる」という状態になります。月次推移グラフやクロス集計(=カテゴリ別×チャネル別のように2軸で件数を出す集計表)は、その上に後から足せる飾りです。まず受け皿と振り分けを作るのが先で、可視化はその次です。
なぜLark Baseを例に挙げるかというと、表計算の手軽さとデータベースの厳密さを両立でき、複数人での同時編集とスマホ閲覧が標準で使えるからです。ただし後述するように、これが唯一の正解ではありません。会社の状況によってはkintoneやCRMのほうが向く場合もあります。
ビフォーアフター:何が変わるか
導入で変わるのは「集計が楽になる」ことだけではありません。本丸は対応漏れと属人化の解消です。
Before(散在・属人化) | After(一元管理後) | |
|---|---|---|
問い合わせの所在 | フォーム・電話メモ・LINEに分散 | 1つの管理表に全件集約 |
対応状況の見える化 | 誰が対応したか口頭確認 | ステータス列で全員が即確認 |
対応漏れ | 数日気づかないことがある | 未対応が一覧で浮き上がる |
属人性 | 担当者の頭の中・個人の受信箱頼み | 仕組みとして全員が引き継げる |
集計の手間 | 毎月Excelに転記して手集計 | データ元と連動して自動更新 |
「集計が自動になる」のは副産物です。経営層にとっての本当の価値は、対応漏れによる失注を防ぐことと、担当者が抜けても問い合わせ対応が止まらないことにあります。問い合わせ1件が新規契約につながる業種なら、対応漏れを月に数件減らすだけで、仕組みのコストはすぐ回収できます。
効果をざっくり試算する
金額で見ておくと判断しやすくなります。以下は数字を当てはめるための一般的な試算で、特定の案件の実測値ではありません。自社の数字を入れてみてください。
問い合わせ1件あたりの平均受注額 × 月の対応漏れ件数 × 失注率の改善分
たとえば問い合わせ1件の平均受注額が10万円、これまで対応漏れで月に2件取りこぼしていたとして、一元管理でそのうち1件を拾えるようになれば、月10万円・年120万円の機会損失を防げる計算になります。あくまで仮の数字ですが、対応漏れを1件減らす価値は、ツールの月額コストとは桁が違うことが多いはずです。
集計工数の削減も乗る。毎月Excelに転記して集計していた作業が消えれば、担当者の時給×作業時間×12か月ぶんが浮きます。ただし主役はあくまで失注防止のほうです。
全体構成とマスク済み実例

仕組みの流れはこうなります。
[HPフォーム]──┐
[広告LP]────┤
[電話メモ]───┼──→ [問い合わせ管理テーブル](受け皿・全件集約)
[LINE]──────┘ │
↓
[数式フィールドで自動振り分け](どのチャネル由来か)
↓
[対応ステータスを全員で更新](未対応/対応中/完了)
↓
[必要なら月次推移・クロス集計を可視化]
ポイントは、入口(チャネル)が何種類あっても、行き着く先は1つの管理表にすることです。フォームからの自動連携、電話メモの手入力、LINEからの転記、入れ方はチャネルごとに違っても、貯まる場所を1つにすれば「全件がここに並ぶ」状態になります。
管理表に並ぶデータのイメージ
言葉だけだと掴みにくいので、管理表がどんな形になるかをサンプルで示します。以下は個人情報を伏せ、内容もダミーに置き換えた例で、実データではありません。
受付日 チャネル区分 相談カテゴリ 対応状況 担当
04/01 10:12 HPフォーム 料金について 完了 Aさん
04/01 14:30 電話 施術の相談 対応中 Bさん
04/02 09:05 広告LP 予約希望 未対応 (空)
04/02 18:40 LINE 場所・アクセス 完了 Aさん
この一覧があるだけで、「未対応」で並んでいる行をフィルタすれば、放置されている問い合わせがすぐ浮き上がります。担当の空欄も一目で分かります。Excelでも似たことはできるものの、複数人が同時に開くと上書き合戦になったり、誰かのローカルに古いファイルが残ったりする。データベース型のツールなら、全員が常に同じ最新のデータを見ます。
振り分けは「数式フィールド」で自動化する
クロス集計や、チャネル別の対応状況を見るには、「このレコードはどのチャネルから来たか」という分類が要ります。これを手入力すると、入力漏れや表記揺れ(「HP」「ホームページ」「Webフォーム」が混在するなど)が起きます。
代わりに、数式フィールドで自動算出します。たとえば流入元の情報からチャネル区分を自動判定する列を作ります。
IF(
CurrentValue.[流入元] が "ある条件" を含む, "HPフォーム",
IF(CurrentValue.[流入元] が "別条件" を含む, "広告LP", "その他")
)
新しい問い合わせが追加されると、チャネル区分が自動で埋まる仕掛けです。手入力に頼らないので、集計が常に正しくなります。ある医療系の案件でも、流入元によって振り分けルールを組み、担当者が分類を意識しなくても自動で仕分けされるようにしました。
この数式フィールドや外部フォームとの自動連携の作り込みは、APIを使えばさらに踏み込めます。Lark Baseをデータベースとして外部システムと連携させる踏み込んだ方法は、Lark BaseのAPIで業務データベースを構築する手順で扱っているので、自動連携まで考える場合はあわせて参照してください。本記事は、その手前の「問い合わせ管理の業務設計と導入判断」に絞ります。
ダッシュボード化は受け皿ができてから
受け皿と振り分けができたら、その上にLark Baseのダッシュボード(=管理表のデータを集計カードやグラフで一覧表示する画面)を足します。よく使うのは次の4枚です。
カード | 種類 | 内容 |
|---|---|---|
月次推移 | 折れ線グラフ | 月ごとの問い合わせ件数の推移 |
カテゴリ×チャネル | クロス集計表 | 相談カテゴリ別×チャネル別の件数 |
チャネル内訳 | 円グラフ | どの入口からの問い合わせが多いか |
未対応サマリ | 数値カード | 未対応件数・当月件数・前月比 |
各カードは管理テーブルを直接参照するので、データが増えれば自動で反映されます。会議で「今月だけ見たい」と言われたら、共通フィルタ(=全カードをまとめて絞り込む条件)を1つ変えるだけです。Excelのように毎回ピボットを作り直す必要はありません。
繰り返しになりますが、可視化は後回しで構いません。まず「全件が1か所に集まり、誰が対応したかが見える」状態を作るのが先です。
どの方式で作るか:選択肢を比べる
問い合わせ一元管理は、Lark Baseだけが正解ではありません。会社の規模・社内のIT人材・予算で、向く道具が変わります。安さではなく「属人化解消と対応漏れ防止にどれだけ効くか・続けられるか」を軸に並べます。
方式 | 向くケース | 注意点(属人化・運用の観点) |
|---|---|---|
Excel・スプレッドシート運用 | 問い合わせが月数件で、担当者がほぼ1人 | 同時編集に弱く、件数が増えると破綻。結局「ファイルの場所」が属人化する |
Lark Base等のローコードDB(=コードをほぼ書かずに作る業務データベース) | 複数チャネルの問い合わせを少人数で回したい。スモールスタートしたい | 自由度が高いぶん、設計を決めずに作ると列がカオス化する。設計の型が要る |
kintone等の国産業務SaaS(=アプリを画面操作で組む国産プラットフォーム) | 社内に非エンジニアの運用担当がいて、長く使い込みたい | ユーザー単位の月額が積み上がる(最小10ユーザーからの契約)。人数が多いとコスト増 |
CRM(HubSpot等=顧客管理に特化した営業支援ツール) | 問い合わせから商談・受注まで一気通貫で追いたい。営業組織がある | 多機能ぶん導入・定着の負荷が高い。問い合わせ管理だけだと過剰になりがち |
自作システム(スクラッチ開発) | 既存システムとの深い連携が必須で、要件が固有 | 初期費用と保守責任が重い。作った人がいなくなると逆に属人化する |
選び方の目安はこうです。問い合わせが少なく担当も少ないならExcelで足りることもあります。複数チャネルが散在して属人化が痛みになっているなら、ローコードDBか国産SaaSが現実的な落としどころ。受注プロセス全体を管理したい営業組織ならCRMが本命になります。自作は、よほど固有の要件がない限り、初期費用と保守責任の重さに見合わないことが多いです。
ある医療系の案件でLark Baseを選んだのは、複数チャネルの問い合わせを少人数で回す状況に対して、同時編集・スマホ閲覧・自動振り分けを低コストで満たせたからです。会社の状況が違えば、最適な方式も変わります。
いくらかかるか:4つのコストを分けて見る
「ツールの月額」だけで判断すると、後から見えないコストに足を取られます。問い合わせ管理の導入では、次の4つを分けて見てください。金額は方式や要件で変わるので、ここでは規模感と「いつ・誰に発生するか」を整理します。
コストの種類 | 規模感の目安 | いつ・誰に発生するか |
|---|---|---|
初期構築 | ローコードDBなら数日〜2週間の作業量。CRMや自作はさらに大きい | 最初に1回。設計・テーブル構築・自動振り分けの作り込み |
運用コスト | ローコードDBは無料〜ユーザー数千円規模/月。CRMは1人あたり月数千円〜が積み上がる | 使い続ける限り毎月。ユーザー数に比例して増えやすい |
保守・改修 | 軽微なら年に数回・数時間。チャネル追加や分類変更のたび | フォームの仕様変更・新チャネル追加・分類見直しのとき |
障害対応・データ整備 | まれ。起きると半日〜。日常的には入力ルールの維持コスト | 自動連携が止まったとき。加えて表記揺れを正す地道な運用 |
見落とされがちなのが一番下の「データ整備」です。仕組みを作っても、入力ルールが守られなければ集計は崩れます。誰がルールを維持するかを決めておかないと、半年で管理表がまた荒れます。安さに飛びつく前に、止まったとき誰が直すのか・ルールを誰が守らせるのかまで決めておくのが安全です。
「初期構築は数日〜数週間、運用はユーザー数しだい、保守は年数回」。この規模感が掴めたら、次は自社でやるか外注するかの判断です。
自社でやるべきか、外注すべきか
「ローコードなら自社で作れそう」と即決する前に、次の3点で判断してください。
判断軸 | 自社向き | 外注向き |
|---|---|---|
社内に設計をリードできる人がいるか | 業務を整理して設計に落とせる人がいる | 現場は忙しく、設計に手が回らない |
問い合わせに個人情報が含まれるか | 含む(どの方式でも個人情報なので扱い設計が要る) | 含む+取り扱いルールを自前で作る自信がない |
作って終わりか、育て続けたいか | チャネル追加や分類変更を自分たちで回したい | 一度設計を固めたら大きく変えない |
2つ目はどの方式でも避けられません。問い合わせデータは氏名・連絡先・相談内容という個人情報の塊です。誰がアクセスできるか、外部連携で情報がどこに流れるか、退職者のアクセスをどう止めるか。この設計を軽く見ると、ツールが何であれ漏洩リスクになります。社内にこの設計をできる人がいなければ、外注したほうが安全です。
外注する場合、見積もりの基準になるのは「初期構築の作業量+個人情報の取り扱い設計+運用ルールの作り込み」です。ツールの月額より、この設計の質が成果を左右します。
こんな場合は一元管理ツールに向かない
正直に、無理にツールを入れないほうがいいケースも挙げておきます。
- 問い合わせが月に数件で、担当も1人:散在も属人化も痛みになっていない。Excelで十分で、ツールはオーバースペック
- 入力ルールを誰も守れない組織状態:仕組みを入れても入力されなければ意味がない。まず運用を回す担当を決めるのが先
- 求めているのが厳密な数値分析:問い合わせ管理ツールの集計は「件数の把握と振り分け」が得意で、複雑な統計分析は苦手。それはBIツールや表計算の仕事
「複数チャネルからそこそこの量が来ていて、誰が対応したか分からなくなっている」会社ほど、一元管理の費用対効果が高くなります。
つまずきポイント
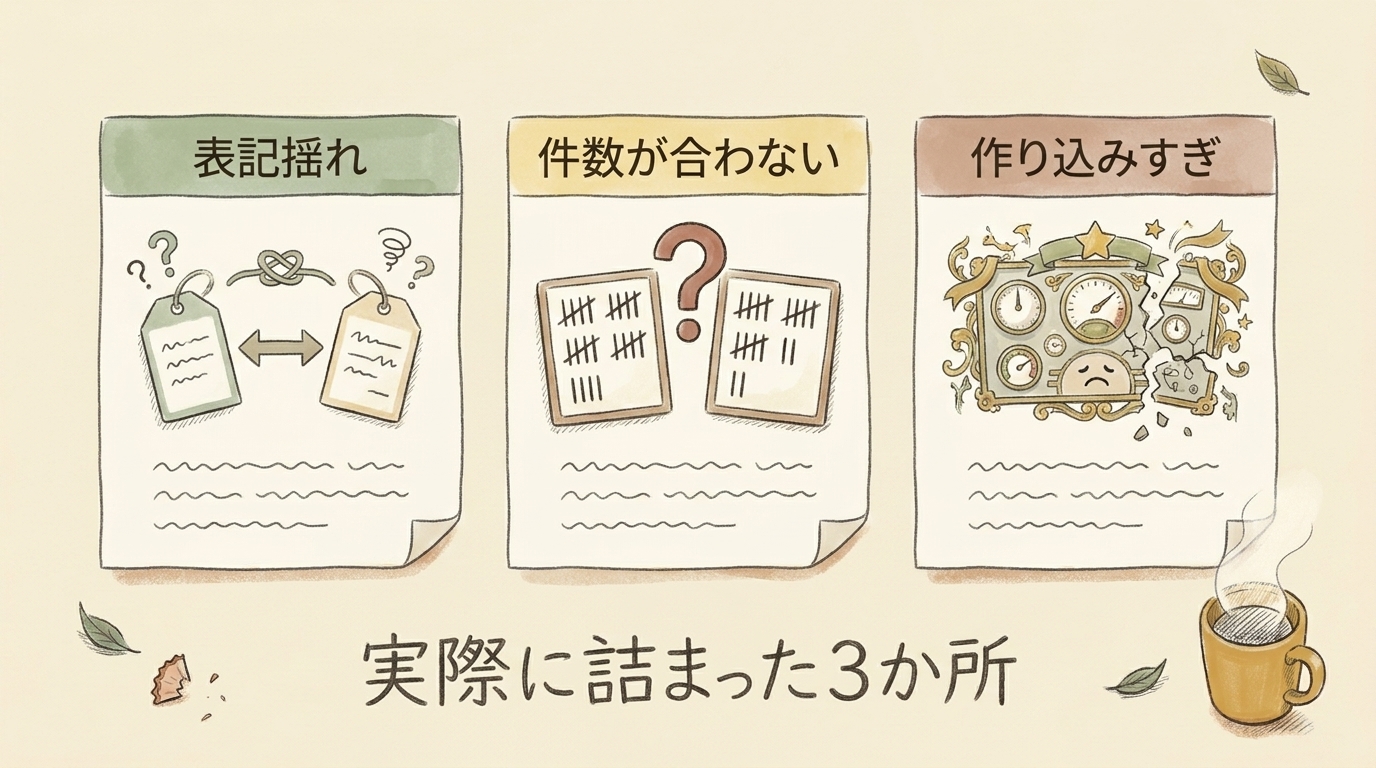
実際に組むときに詰まった点を挙げます。自社で挑戦する方も、外注先に確認する方も、知っておくと話が早いです。
つまずき1:チャネルの自動振り分けが表記揺れで崩れる
数式フィールドで「流入元がこの条件ならHPフォーム」と振り分けても、フォーム側の仕様が変わったり、流入元の表記がわずかに変わったりすると、判定が外れて「その他」に落ちます。気づかないうちに集計が崩れているのが厄介なところ。導入直後と、フォームを変更したときは、サンプルで振り分けが正しいか必ず確認しておきたいところです。
つまずき2:件数が元のExcelと合わない
移行後、「ツールの集計値が前のExcelと違う」と現場が不信感を持つことがあります。多くは数式フィールドの条件ミスか、重複登録です。移行直後に、同じ期間でExcelとツールの件数を突合して、一致を確認しておくと信頼される。
つまずき3:作り込みすぎて現場が入力しなくなる
最初から項目を増やしすぎると、現場が入力を面倒がって埋めなくなります。そうなると管理表が虫食いになり、集計も対応状況も当てになりません。まず必須項目(受付日・チャネル・相談内容・対応状況・担当)に絞って、運用が回ってから項目を足すのが定着のコツです。道具を豪華にすることが目的化すると、かえって使われなくなります。
導入前チェックリスト
着手する前に、次を整理しておくと設計がぶれません。
- 問い合わせの入口は何種類あるか(HPフォーム/LP/電話/LINE など)→ 集約先と連携方法が決まる
- 月にどれくらい来るか(数件/数十件/数百件)→ Excelで足りるか、ツールが要るかが決まる
- 誰が対応するか・何人で回すか→ 同時編集や権限設計の要否が決まる
- 個人情報の取り扱いルールはあるか(アクセス権・退職者対応・外部連携)→ 漏洩リスクの設計
- 入力ルールを誰が維持するか→ 決めないと半年で管理表が荒れる
- 本当に必要な項目は何か(最初は最小限に)→ 作り込みすぎを防ぐ
この6つが決まれば、方式選びと見積もりの精度が一気に上がります。
まとめ:可視化より先に「全件が見える受け皿」を作る
問い合わせ管理の一元化で大事なのは、凝ったダッシュボードではありません。
- まず全件が1か所に集まる受け皿と、チャネルを自動で振り分ける仕組みの2部品から始める
- 本当の価値は集計の自動化ではなく、対応漏れによる失注防止と、担当が抜けても止まらない脱属人化
- 方式は安さでなく「属人化解消にどれだけ効くか・続けられるか」で選ぶ。Excel・ローコードDB・国産SaaS・CRM・自作にそれぞれ向き不向きがある
- コストは初期構築・運用・保守・データ整備を分けて見る。見落としがちなのは入力ルールの維持
- 作り込みすぎない。最小限の項目で運用を回してから育てる
問い合わせは新規顧客の入口です。その入口の管理が一番属人化していると、知らないうちに失注が積み上がります。「データはあるのに誰が対応したか分からない」状態を、「全件が見えて、誰でも引き継げる」状態に変える。これが問い合わせ一元管理の本当の効きどころです。
問い合わせ管理の散在・属人化でお困りなら
「複数の入口から来る問い合わせを、誰が・どこまで対応したか把握できていない」。そう感じているなら、最初にやるべきは仕組みづくりより、現状の整理です。入口は何種類あるか、月にどれくらい来るか、個人情報をどう守るか、どの方式が自社に合うか。この線引きが、導入の成否を最初の設計で分けます。
f2t.jpでは、問い合わせの入口の棚卸しから、一元管理の方式選定・設計・構築(個人情報の取り扱いを含む)、運用ルールづくりまで一貫してお手伝いしています。まずは「自社の問い合わせがどこに散らばっていて、どの方式なら属人化を解消できるか・費用対効果はどうか」を一緒に整理するところから始められます。お問い合わせフォームから、自社の問い合わせ管理の悩みをご相談ください。
この記事のテーマに合うサービス:AIエージェント活用設計
AIエージェントを「使える形」まで設計する



