顧客情報をAIに渡して大丈夫か。個人情報(PII)の漏洩を仕組みで防ぐ3段階導入(Claude Code hook)

顧客情報をAIに渡して大丈夫か。個人情報(PII)の漏洩を仕組みで防ぐ3段階導入(Claude Code hook)
顧客リストをAIに読ませて分析する。問い合わせ履歴を要約させる。AIを業務に入れるほど、こうした「AIに社内データを渡す」場面は増えていきます。便利になる一方で、そのたびに「うっかり個人情報をAIに見せてしまう」入口も増えている。この感覚に心当たりのある方は多いと思います。
たとえば開発支援ツールのClaude Code(クロードコード、ターミナルでAIにコードやファイルを扱わせる開発ツール)で顧客データの入ったファイルを開く。その瞬間、氏名や電話番号はAIの作業メモリに載ります。意図せず別の出力に混ざる、外部サービスに渡る。運用が長く続くほど、その確率は積み上がっていきます。
ここで「気をつけよう」と現場に呼びかけても、事故は減りません。人の注意力には限界があり、AIは疲れずに大量のファイルを読みます。守るなら、人の意識ではなく仕組みで止める必要がある。この記事では、コードに一切手を入れずに「検出 → マスク → ブロック」を段階導入する設計を、自社で実際に運用している例として紹介します。AIを業務利用している会社が、個人情報をどう構造的に守るか、自社でやれるか外注すべきかを判断できるところまで書きます。
なお本文ではPII(=個人を特定できる情報。氏名・電話番号・メールアドレスなど)という略語を使います。
結論:hookで「コード変更なし」に検出・マスク・ブロックを3 Stageで入れる
Claude Codeには PostToolUse hook(ポストツールユースフック)という仕組みがあります。AIがファイルを読んだりコマンドを実行したりするたび、その出力に外部スクリプトを割り込ませられる機構です。これを使うと、業務システムのコードには一切触らず、PII の検出と防御を後付けで差し込めます。
最小構成はこうなります。
役割 | やること | どう実現するか |
|---|---|---|
① 割り込み口 | AIがファイル読取・コマンド実行したら自動で起動する | PostToolUse hook(=AIの動作の後に処理を差し込む仕組み) |
② 検査役 | 出力に PII が何件・どの種類あるか調べる | 正規表現で氏名・電話・メール等を判定するスクリプト |
③ 記録/加工役 | 件数を記録する、または PII を伏せ字に置換する | Stageに応じて記録だけ/マスク/ブロックに切り替える |
要点は2つあります。1つ目は、業務システムのコードを書き換えずに防御を後付けできること。2つ目は、いきなり全部ブロックしないことです。hook は AI が見る出力そのものを書き換える力を持つので、誤検知でデータが壊れると作業が止まる。だから観測だけの段階から始めて、実態を測ってから防御を強めます。
具体的には3つの Stage に分けます。
- Stage 1(detect-only):検出してログに記録するだけ。出力は一切触らない
- Stage 2(選択マスク):高リスクの経路に限定して、PII を伏せ字に置換する
- Stage 3(block):外部送信の直前で、確度の高い漏洩だけ実行を止める
この順番が肝心です。Stage 1で「どこに、どれくらいの頻度で PII が出るか」を実測しないまま、いきなりマスクへ進むと事故になります。なぜそう言い切れるか。観測だけの Stageundefinedを本番に入れた初日に、それを痛感する出来事があったからです。
detect-onlyを先に置く理由:初日に判明した誤検知
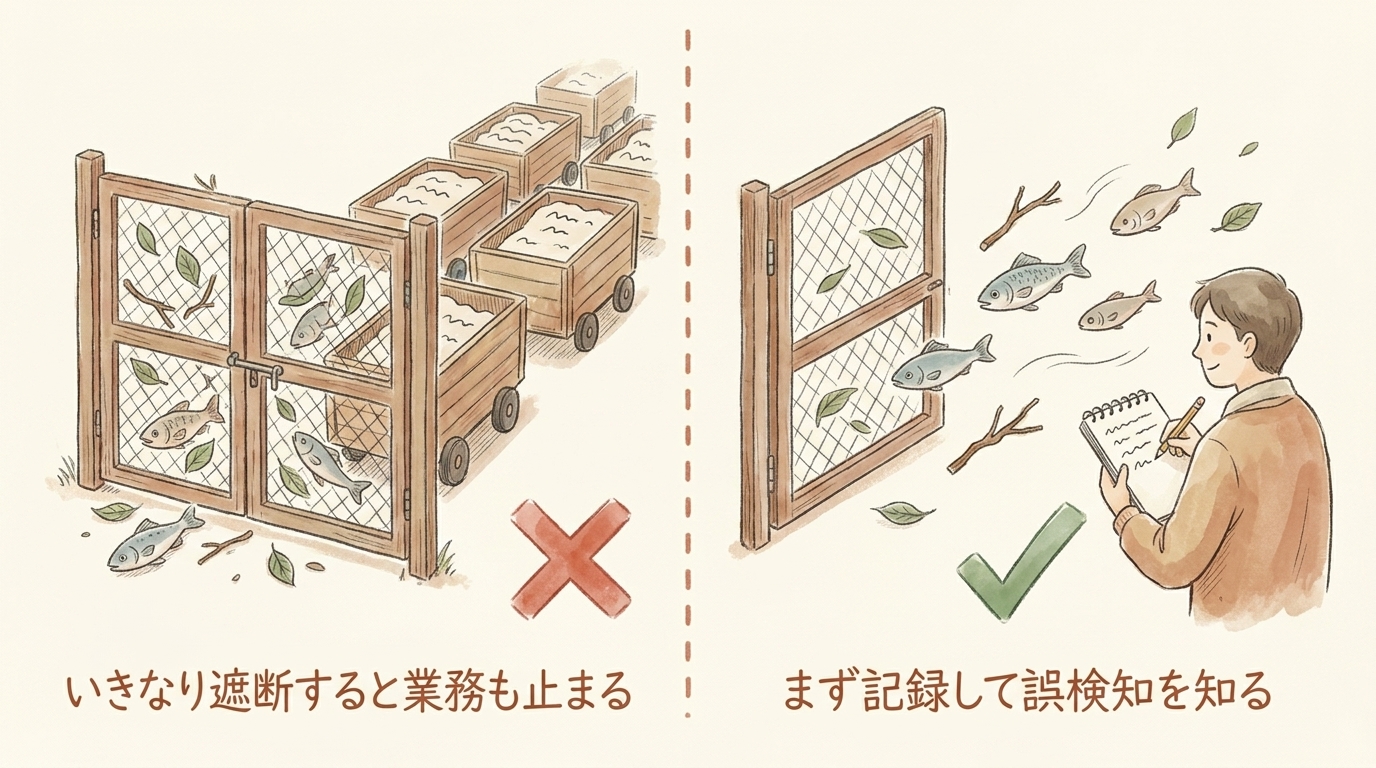
ある案件で Stageundefinedを本番投入したとき、初日に大きな発見がありました。
PII 検出スクリプトは、正規表現で `YYYY-MM-DD` 形式の日付(1900〜2099年)を生年月日として拾うよう作っていました。判定としては合理的です。ところが、コマンド実行の出力には、gitのコミット日、ログのタイムスタンプ、ファイル名の日付が大量に含まれる。結果、ほぼすべてのコマンド出力が「生年月日あり」と判定されました。
もし先に Stage 2(マスク置換)を入れていたら、コミットログの日付が `[DATE_OF_BIRTH_1]` のような伏せ字に書き換えられ、AIはバージョン管理の文脈を完全に見失っていたはずです。日付が消えた状態で「いつのコミットか教えて」と聞いても、まともな答えは返りません。
detect-only だったから、ログに「date_of_birth: 47件」と記録されるだけで済みました。出力は無傷。このログを見て初めて「日付パターンは Stageundefinedで検出から外すか、同じ行に『生年月日』『DOB』『誕生日』といった文脈語があるときだけ拾う」と判断できた。観測していなければ、誤検知の存在にすら気づけませんでした。
先に計測し、誤検知の実態を掴んでから防御強度を上げる。この順番を守らないと、hook は防御ではなく業務の妨害になります。最初から全ブロックにすると、こうした誤検知で作業が止まり、現場が hook を無効化して終わる。それでは何も守れません。
3 Stageの設計詳細
Stage 1: detect-only(観測だけ)
PostToolUse hook で、ファイル読取とコマンド実行の出力を PII 検出スクリプトに通します。スクリプトがやるのは「何件、どの種類(メール / 電話 / 氏名 / 生年月日 など)が検出されたか」を記録ファイルに書くことだけ。出力そのものには触れません。記録される1行のイメージはこうです。
```2026-05-26 / ファイル読取 / 検出3件 / 種類: メール, 電話```
この段階で重要なのは、何を「やらない」かです。出力は書き換えない。AIの待ち時間に影響しないよう、検査は処理の裏で非同期に走らせる。記録には生の PII を残さず、件数と種類名だけにする(記録ファイル自体が新たな漏洩経路になるのを防ぐため)。そして hook が失敗しても必ず通過させ、通常の作業を止めない。要するに「観測に徹して、何も壊さない」のが Stageundefinedの設計思想です。
これを1週間ほど回して、次を測ります。
- 種類別の検出件数
- 誤検知が多い種類(前述の生年月日など)
- 本当に PII が出る経路(顧客ファイルの読取、特定のデータベース照会の出力など)
ここで集まる実測データが、次の Stage の設計精度を決めます。
Stage 2: 選択マスク(高リスク経路だけ伏せ字に)
Stageundefinedの実測をもとに、高リスクの経路だけにマスクをかけます。すべての読取・全コマンドに一律でかけるのではありません。たとえば「顧客管理系のファイルパスに一致する読取」「特定テーブルへの照会結果を含む出力」に絞る。Stageundefinedで「ここに本物の PII が出る」と分かった経路にだけ適用するわけです。
マスクの形式には安定仮名化を使います。同じセッション内で、同じメールアドレスは常に `[EMAIL_1]`、同じ電話番号は常に `[PHONE_1]` という同一の伏せ字に置き換える方式です。こうすると、AIは「さっき出てきた `[EMAIL_1]` と同じ人物だ」という文脈を保てる。毎回ランダムに変わる伏せ字だと、集計や名寄せが壊れます。
Stageundefinedは Claude Code が見る出力を実際に書き換えるため、リスクが一段上がる段階です。具体的には次のような問題が起きえます。
- 顧客IDやURLの一部がメールアドレスと誤認され、マスクされて分析できなくなる
- hook が失敗したとき、元の出力がそのまま素通りする
- AIが見ている出力と、人がターミナルで見る出力がズレて、原因調査がしにくくなる
だから Stageundefinedに進む判断は、Stageundefinedの誤検知率データを握ってから下します。観測の裏付けなしに踏み込まない。これが鉄則。
Stage 3: block(外部送信の直前で止める)
Stageundefinedまでは記録とマスクで対処しますが、Stageundefinedは「止める」です。外部サービスへの送信やファイル書き出しの直前で、確度の高い PII 漏洩を検出したら、その実行そのものをブロックする。
Stageundefinedが実運用で要る場面は限られます。Stage 1・2 で大半のリスクは潰せるので、「マスクでは足りない経路」が実測で見つかってから設計する、くらいの位置づけで十分です。最初から作り込む必要はありません。
なぜ段階導入か:CRITICALの線引き
Stage ごとにリスクの重さが違います。ここを混ぜると設計を誤ります。
Stageundefinedは低リスクです。出力を書き換えない。裏で動く。失敗しても素通りする。最悪でも「記録が増える」だけ。即日入れて問題ありません。
Stage 2以降は CRITICAL(取り消しが効きにくく、影響が大きい操作)です。AIが受け取る情報そのものを改変する。誤検知でデータが欠ければ、その上に乗る判断もすべて歪む。だから承認を通してから入れ、限定された経路から始め、問題がなければ範囲を広げる。
この「低リスクは即投入、高リスクは実測してから」という段階設計は、PII 検出に限らず、hook を使ったあらゆる防御策に応用が効きます。
何が変わるか:ルールなし運用 vs hook導入

ここまでが設計の中身です。ここからは経営層・情シスが投資判断に使えるよう、判断材料を並べます。まず、社内ルールだけの運用と hook を入れた運用で、何が変わるかです。
Before(ルールと注意喚起だけ) | After(hook導入後) | |
|---|---|---|
漏洩の防ぎ方 | 「気をつける」という人の意識頼み | 出力を機械が自動で検査する |
検知のタイミング | 事故が起きてから気づく(または気づかない) | AIが読んだ瞬間に検出される |
誰がやるか | 各担当者の注意力に依存 | 仕組みが全員ぶん一律に回す |
属人性 | 担当が代わると守りが緩む | 誰が使っても同じ守りが効く |
記録 | どこで PII に触れたか残らない | いつ・どの経路で何件触れたか記録が残る |
差は「人の注意力に依存するかどうか」の一点に集約されます。ルールと教育は守りの土台として要りますが、それだけでは「うっかり」を構造的には防げない。hook はその穴を、人の意識の外で埋めます。
どの方式で守るか:3つの選択肢を比べる
PII 漏洩を防ぐ手段は hook だけではありません。社内規程、教育、hook の3つを、同じ軸で並べます。経営判断で見るべき軸は「人の注意力に依存するか」です。
方式 | 人の注意力に依存するか | 向くケース | 注意点 |
|---|---|---|---|
社内規程(禁止事項を文書化) | 完全に依存する | 守るべき線引きを全員に示す土台として | 読まれない・守られないと意味がない。事故の検知も止めもできない |
教育・研修(注意喚起する) | 完全に依存する | 担当者のリテラシーを底上げしたいとき | 効果が時間で薄れる。新人が入るたびに必要。やはり「うっかり」は残る |
hook(仕組みで自動検査・遮断) | 依存しない | AIに渡るデータを構造的に守りたいとき | 作るのにツールの知識が要る。誤検知対策に観測期間が必要 |
規程と教育は「人がルールを守る前提」で成り立ちます。前提が崩れた瞬間(忙しい・知らない・うっかり)に守りが消える。hook は人がルールを忘れても動き続けます。3つは対立するものではなく、規程と教育で線引きを示し、hook でその線を機械的に担保する、という重ね方が現実的です。
こんなケースには hook 導入が向かない
正直に、向かない場面も挙げておきます。
- AIに社内データをほぼ渡していない:そもそも PII がAIに載らないなら、構造的防御の前に運用ルールの整備で足りる
- 扱うデータに個人情報がそもそも含まれない:公開情報や匿名データだけなら、誤検知のコストのほうが大きい
- 1回限り・短期の検証用途:作って維持する手間が、守る価値を上回る
- 社内にツールを触れる人がゼロで、外注の意思もない:作っても誰も保守できず、誤検知が出たとき止まったまま放置される
逆に「顧客・患者データを継続的にAIに渡す」「複数の担当者が同じ環境を使う」「漏洩したときの被害が大きい業種」ほど、hook による構造的防御の費用対効果が高くなります。とくに医療系の案件のように、扱う情報の機微度が高い現場では、人の注意力に頼る運用そのものがリスクになります。
導入前チェックリスト
着手する前に、次を整理しておくと設計がぶれません。外注先に相談するときも、この5つが決まっていると話が早く進みます。
- [ ] AIに渡しているデータに PII が含まれるか(含まないなら hook は不要)
- [ ] PII が出る経路はどこか(顧客ファイルの読取/特定DBの照会出力 など)
- [ ] AIに渡した出力は外部サービスに再送信されるか(されるなら Stageundefinedの検討が要る)
- [ ] 観測期間(Stage 1)を何週間とれるか(最低1週間は実態計測に充てる)
- [ ] 誤検知が出たとき誰が判定ルールを直すか(保守の担い手を先に決める)
この5つが決まれば、あとは前述の最小構成を組み、Stageundefinedから順に進めるだけです。
AIを業務に入れる際の情報管理は、hook のような技術的防御だけで完結しません。何を渡してよいか・どのツールが安全かといった運用面の整理も要ります。中小企業がAIを使う前に押さえる観点は、中小企業向けAIセキュリティチェックリストに別途まとめました。技術的防御と運用ルールはセットで考えるのが安全です。
アンチパターン:やってはいけない4つ
いきなりフルブロック
「個人情報は危険だから全部止めよう」と、Stageundefinedを飛ばしてブロックから入る。日付・URL・IDなどの誤検知で作業が頻繁に止まり、現場が hook を無効化して終わる。結果、防御は何も残りません。
全経路を一律マスク
読取もコマンドも全部マスクにかける。gitログの日付、ライブラリ導入時の出力、ファイル一覧。あらゆる出力に検出が走り、AIのコンテキストが伏せ字だらけになる。何の作業をしているかAIが見失い、出力品質が落ちます。
生のPIIをログに残す
検出ログに「○○さんのメールアドレス○○@example.com を検出」と書いてしまう。記録自体が新たな漏洩経路になる。ログに残すのは件数と種類名だけにする。
失敗したら全停止にする
hook がエラーを返したときに、AIの動作そのものを止める設計。hook のちょっとしたバグでツール全体が使えなくなり、復旧に時間を食う。Stage 1・2 の hook は失敗しても通過させる(素通り)を基本にする。例外は Stageundefinedのブロックだけで、ここは止める側に倒すのが正しい。
まとめ
Claude Code PII 検出 hook で個人情報を構造的に守る要点を整理します。
- PostToolUse hook を使えば、業務コードを変えずに PII 検出を後付けできる
- Stage 1(観測だけ)を先に入れ、誤検知の実態を1週間ほど計測する
- Stage 2(選択マスク)は高リスク経路に限定し、安定仮名化で文脈を保つ
- Stage 2以降は CRITICAL 扱い。承認を通し、限定経路から段階導入する
- 最初から全ブロックは逆効果。実測が先、防御が後
守りの本質は「人の注意力に頼らないこと」です。規程と教育で線引きを示しつつ、その線を機械が自動で守る。observe(観測)から始めて実態を掴み、危ない経路から順に塞いでいく。これが、AIを業務に入れながら個人情報を守る現実的な道筋になります。
AI業務利用時の個人情報保護を設計したい方へ
「AIに顧客データを渡しているが、漏れないか不安」「どのデータならAIに見せていいか、社内で線引きできていない」。AIを業務に入れ始めた会社で、こうした声はよく聞きます。技術的な防御の仕組みづくりと、運用ルールの整理は、最初の設計でほぼ決まります。f2t.jpでは、AIに渡してよいデータの線引きから、検出・マスクの仕組み構築、運用ルールの整備までを一貫してお手伝いしています。お問い合わせフォームから、自社のAI利用で「個人情報をどう守るか」をご相談ください。



