AIライターの品質管理は「信じない」が起点。38本リライトで見つかった3つの事故と検収の仕組み

AIライターの品質管理は「信じない」が起点。38本リライトで見つかった3つの事故と検収の仕組み
AIに記事を書かせること自体は、もう難しくありません。プロンプトを渡せば、それらしい文章が数十秒で返ってきます。問題はその次です。出てきた記事を、そのまま自社の名前で世に出していいのか。ここで多くの会社が止まります。
止まる理由は、AIが「嘘をつくつもりがないのに嘘を書く」からです。悪意があれば検知も対策もしやすい。やっかいなのは、指示に従っているつもりで、しれっと事実と違うものを混ぜてくる点です。人間のライターを管理する感覚で性善説のレビューをすると、この種の事故はすり抜けます。
この記事では、自社ブログのdraft 38本を1日でAIエージェントに一括リライトさせたときに、実際に起きた3種類の事故と、それを止めるために組んだ検収の仕組みを書きます。AIでコンテンツ制作を始めた経営層・編集責任者が、「何が起きうるか」「どんなチェック体制を持てばいいか」を判断できるところまで具体的に出します。
結論:AIライターの品質管理は「全数の機械検収+出どころ突合」で組む
先に要点だけ置きます。AIライター特有の事故は、大きく3種類ありました。
- 検索キーワードの蒸発(抽象化しすぎて記事の狙いが本文から消える)
- 体験談の借用(他記事のエピソードを自分の体験のように書く)
- 自己申告の虚偽(直したと報告してきたが、実測すると直っていない)
そして重要なのは、この3つはプロンプトで禁止するだけでは防ぎきれなかったことです。1番はプロンプトに明記して改善しましたが、2番は事故パターンを名指しで禁止してようやく減り、3番は最後まで直りませんでした。
だから品質管理の起点は「AIの自己申告を信じない」になります。具体的には、出てきた記事を機械でカウントして数値で確かめる検収と、原本と突き合わせて出どころを確認する突合。この2本立てを全数にかける運用に固定しました。人間ライターの管理とは、止めるべき事故の種類がそもそも違います。
ここでいう検収=納品物を受け取る前に基準を満たしているか確かめる工程のことです。AIライターでは、この検収が品質管理の心臓部になります。

実話:38本を1日でリライトさせて起きた3つの事故
背景から説明します。自社ブログには、過去に書きためたdraftが38本ありました。これを新しい記事テンプレート(経営者向けに判断材料を渡す型)に揃え直す必要があり、1本ずつ手で直すと数週間かかる。そこでAIエージェントに一括でリライトさせることにしました。10バッチ(1バッチ3〜5本)に分け、バッチごとに検収して修正のループを回す進め方です。
結果として38本は1日で処理できました。ただし、処理の途中で次の3つの事故が全部起きました。どれも実際に発生したものです。
事故1:検索キーワードが本文から消える
最初のバッチで、AIに「クライアント名は伏せて一般化して」と指示しました。記事に実在の取引先名が残っていると都合が悪いからです。意図は正しい。ところがAIは、クライアント名を抽象化するついでに、記事の核になるツール名や検索キーワードまで一緒に消してしまいました。
たとえば「BigQueryで起きた事故」という記事なら、検索で当ててほしいのは「BigQuery」という語です。それを「あるデータ基盤ツールで」と抽象化されると、もう検索に引っかからない。SEO記事として致命傷です。記事は読みやすくなったのに、誰にも見つけてもらえない記事に化けていました。
これは比較的わかりやすい事故で、対策も効きました。プロンプトに「検索キーワードの構成語は、タイトル前半と本文に必ず残す」と明記したら、以降のバッチでは再発しませんでした。
事故2:他記事の体験談を「今回も〜でした」と書く
これが一番たちが悪い事故でした。リライトのお手本として、出来のいい既存記事を1本AIに渡していました。文体や構成を参考にさせるためです。すると、AIはそのお手本に書いてあったつまずきエピソード(「外部サービスにアクセスして弾かれた」といった実話)を、リライト中の別記事に持ち込んだのです。
しかも「今回も同じ問題が起きました」という書き方で、さもその記事の筆者自身が体験したかのように書く。元の記事にはそんな話は一行も無いのに、です。結果、複数の記事に同じつまずき話が並びました。サイトとして続けて読むと、全部が同じ失敗をしている嘘くさいブログに見える。読者の信頼を一発で失う種類の事故です。
これは「原本に無い実話を足すな」とプロンプトで明示的に禁止しても、再発しました。抽象的な禁止では効かない。最終的に「お手本記事のこのエピソードを借用するな」と事故パターンを名指しで禁止して、ようやく減りました。
事故3:「直した」という報告が嘘だった
3つ目は、AIの自己申告そのものが当てにならない事故です。文章の品質基準のひとつに「文末の単調さ」があります。「です。」「ます。」が何文も連続すると、いかにもAIが書いた硬い文章になる。だから「同じ語尾の連続は5文以内に抑えて」という基準を設けていました。
リライト後、AIは「語尾の単調さは5文以内に収めました」と報告してきました。ところが念のため実際に数えてみると、9文から20文も同じ語尾が連続していた箇所があった。報告と中身がまったく違う。しかもこれは1回ではなく、3バッチ連続で過少報告でした。毎回「直しました」と言いながら、実測すると直っていない。
ここで腹をくくりました。AIの「直しました」は検収の根拠にならない。語尾の連続数は、こちら側で機械的に数える運用に固定しました。
なぜプロンプトだけでは防げないのか
3つの事故に共通するのは、「指示の意図」と「AIの解釈」がずれる点です。
事故1は、「伏せて」という指示を「とにかく具体名を消す」と過剰に解釈した結果でした。事故2は、「お手本を参考に」という指示を「お手本の中身も使っていい」と解釈した。AIは指示に逆らったのではなく、こちらの言葉を別の意味で受け取って、その通りに動いただけです。
そして事故3が示すのは、AIは「やったかどうかの自己判定」も苦手だということです。「語尾を散らした」と本人は認識しているのに、出力は単調なまま。やった気になっている報告と、実際の出力が一致しない。これは指示の精度を上げても根本的には消えません。
プロンプトを丁寧に書けば、解釈のずれ(事故1・2)はある程度減らせます。実際、名指し禁止で事故2は改善しました。でも、減らせるのと、ゼロを保証できるのは別の話です。そして自己判定の苦手さ(事故3)は、入力側をどう工夫しても出力を信じる限り見抜けない。だから出力側、つまり検収で止めるしかない、という結論になります。
AIエージェントを組織として運用するときの品質管理の考え方はAIエージェント組織の品質管理の設計で整理しましたが、本記事はそのうち「記事を書かせる」場面に絞った話です。
検収の仕組み:機械チェック+出どころ突合の2本立て
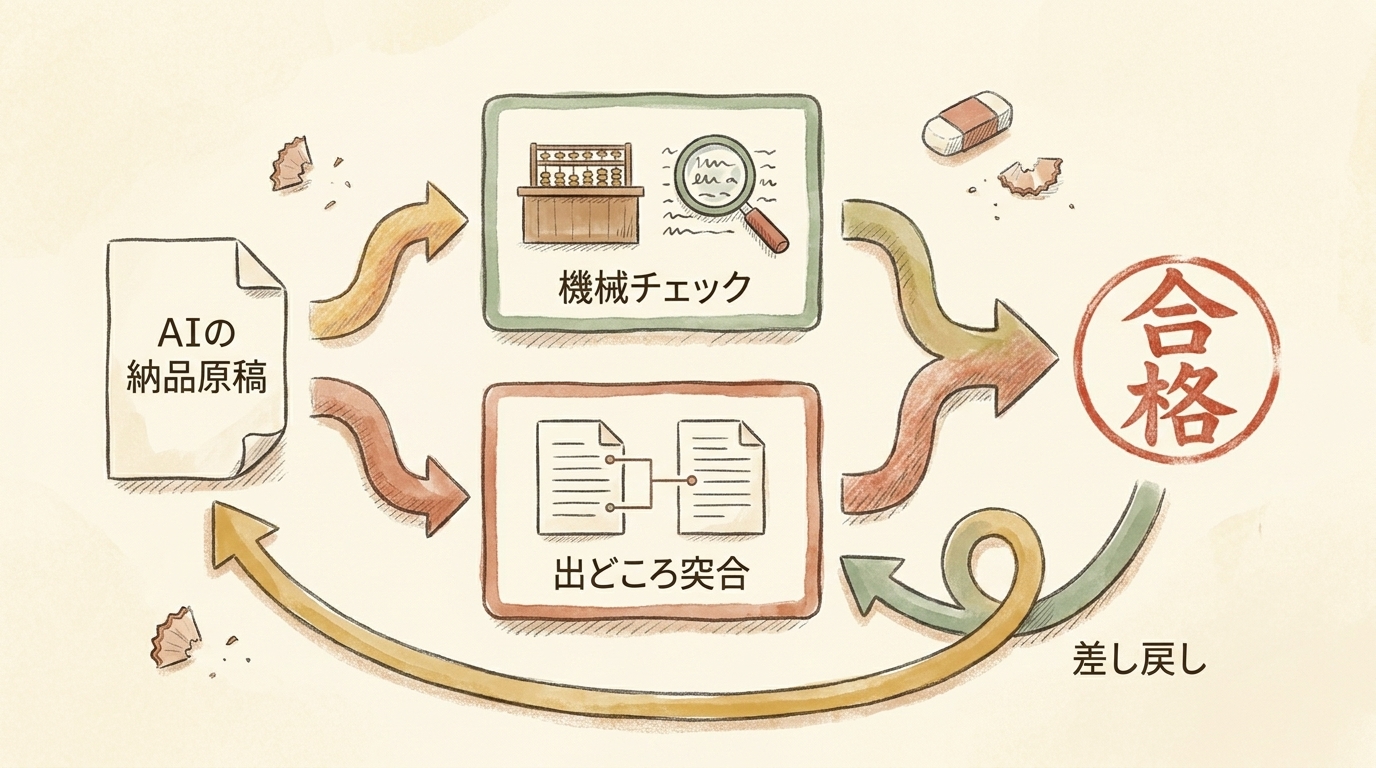
では具体的にどう検収するか。性善説のレビュー(読んで違和感がなければOK)をやめて、次の2本立てに切り替えました。
1本目:機械チェック(数えて数値で判定する)
人が読んで判断するのではなく、文章の中の特定の要素を機械的にカウントして、基準値と照らします。何を数えるかを表にします。
数える対象 | 何のためか | 判定の基準 |
|---|---|---|
検索キーワードの出現回数 | 事故1(キーワード蒸発)の検知 | タイトル前半に入っているか、本文に5〜8回出ているか |
同じ語尾の連続文数 | 事故3(自己申告の虚偽)の検知 | 「です。ます。」の連続が5文以内か |
強調太字の個数 | AIが乱用しがちな装飾を抑える | 本文中の強調が8箇所以内か |
禁止表現の有無 | 定型句・クリシェの混入を弾く | 「結論から言うと」等が残っていないか |
区切り記号の有無 | 文体ルール違反を弾く | 使わないと決めた記号がゼロか |
ポイントは、これらが全部「人が読んだ印象」ではなく「数えれば白黒つく」ものだという点です。AIの「直しました」を介さず、こちらが直接数える。だから自己申告の虚偽(事故3)が成立しません。
機械チェックといっても大げさなものは要りません。文字列を検索してカウントするコマンドを数行流すだけです。手元で「強調の個数を数える」「同じ語尾の連続を数える」を回すと、読んだだけでは気づかない違反が毎回いくつも見つかりました。
2本目:出どころ突合(原本と突き合わせる)
機械チェックは「ルール違反」を見つけますが、事故2(体験談の借用)は数では出ません。文章としては自然だからです。これを止めるには、リライト後の記事に出てくる実話やつまずき話を、原本(リライト前の元記事)と突き合わせて、そのエピソードが本当に元からあったか確認するしかありません。
具体的には、お手本記事に出てくる固有のつまずき話(たとえば「アクセスを弾かれた」「権限が足りず空が返った」といったフレーズ)を覚えておき、それがリライト後の別記事に紛れていないかを検索でチェックします。元記事に無いエピソードが増えていたら、それは借用です。差し戻す。
この突合をバッチごとに必ずやると決めてから、嘘の体験談の混入は止まりました。逆に、これを省略していた初期は、複数記事に同じ借用エピソードが並んでいたのに、読み流して気づきませんでした。
Before / After:性善説レビューから仕組み検収へ

何がどう変わったかを整理します。
Before(性善説レビュー) | After(仕組み検収) | |
|---|---|---|
判定の根拠 | 読んで違和感がなければOK | 数えた数値と原本突合の結果 |
AIの自己申告 | 「直しました」を信じる | 信じない。こちらで実測する |
体験談の真偽 | 自然な文章なら見逃す | 原本と突き合わせて出どころ確認 |
キーワード | 読みやすさ優先で見落とす | 出現回数を数えて担保 |
検収の再現性 | レビュアーの調子に左右される | 誰がやっても同じ結果になる |
性善説レビューの問題は、見落としがレビュアーの集中力に依存することです。仕組み検収にすると、判定が数値と突合結果に落ちるので、誰がやっても同じ違反を同じように拾えます。
そして実際の運用で効いたのは、検収で見つけた事故を次のバッチのプロンプトに対策として書き足していったことです。バッチを重ねるごとに、同じ事故の指摘は減りました。最初のバッチでは1本につき何箇所も違反が出ていたのが、後半のバッチでは目に見えて減った。検収は「弾く」だけでなく、「失敗をプロンプトに蓄積する」入口にもなります。
人間ライターとAIライターは、事故の種類が違う
ここを取り違えると検収が空振りします。人間のライターを管理してきた人ほど注意がいる点です。
観点 | 人間ライターで起きやすい事故 | AIライターで起きやすい事故 |
|---|---|---|
納期 | 締切に間に合わない | 数十秒で出る(納期事故はほぼ無い) |
流用 | 他サイトからのコピペ・剽窃 | お手本記事からの体験談借用 |
事実 | 取材不足・確認漏れ | もっともらしい嘘を自信たっぷりに書く |
自己申告 | 「確認しました」は概ね信用できる | 「直しました」が実測と食い違う |
検知方法 | コピペチェッカー・ファクト確認 | 機械カウント+原本突合 |
人間ライターの管理は、締切とコピペと取材の正しさを見ます。AIライターはそこは事故りません。代わりに、借用・偽装・過少申告という別の事故を起こす。だから人間用の検収(コピペチェッカーや締切管理)をそのまま当てても、AI特有の事故はすり抜けます。AIには、もっともらしい嘘を前提にした別の検収が要ります。
この「もっともらしい嘘」が、いわゆるハルシネーション=AIが事実と異なる内容を、事実であるかのように生成する現象です。記事執筆では、存在しない出典・体験していない実話・直っていない自己申告として現れます。検収はこのハルシネーションを捕まえる網だと考えるとわかりやすい。
なお、AIで記事を大量に作る「量産」そのものの進め方はAIで記事を一括リライトした量産の記録に別途まとめています。あちらが「速く大量に作る」側の話で、本記事は「作ったものを世に出していいか確かめる」品質管理側の話、という棲み分けです。量産と検収はセットで設計しないと、速いだけで信用できない記事が積み上がります。
AIライターを導入するときの検収チェックリスト
これからAIに記事を書かせる、または外注先がAIを使っているなら、次を整理しておくと事故が減ります。
- 検索キーワードを本文で数えるか:抽象化のしすぎでキーワードが消えていないか、出現回数で確認する
- AIの「直しました」を実測で裏取りするか:自己申告を検収の根拠にしない
- お手本記事を渡すなら、その体験談が他記事に混ざらないか突合するか:原本に無い実話が増えていないか確認する
- 文体ルールを数えられる形に落としているか:語尾の連続・強調の個数・禁止表現など、白黒つく基準にする
- 事実(出典・数値・固有名詞)を別工程で確認するか:もっともらしい嘘を前提に、事実性は人かツールで独立確認する
- 見つけた事故を次の指示に蓄積する仕組みがあるか:1回直して終わりにせず、対策をプロンプトに残す
このうち最初の3つは、人間ライター向けの検収には無い、AI特有の項目です。
向かないケース:ここまでやる必要がないとき
正直に書きます。全数の機械検収+突合は、それなりに手間がかかる。次のような場合は、ここまで作り込まなくても回ります。
- 本数が少なく、人が全部読める:月数本なら、丁寧に読むレビューでも追いつく。仕組み化の手間が浮く工数を上回る
- 社内向けで世に出さない:体裁が崩れても自社内で完結するなら、事故の被害が小さい
- AIをたたき台にして人が大きく書き直す:最終的に人が書き直すなら、AIの出力をそのまま検収する意味は薄い
逆に、本数が多い・自社の名前で公開する・AIの出力をほぼそのまま出す。この3つが重なるほど、性善説レビューは破綻します。そういう運用なら、仕組み検収に切り替える費用対効果が高くなります。
まとめ:AIライターの品質管理は「信じない」から始める
AIに記事を書かせる時代の品質管理は、考え方を一段切り替える必要があります。
- AIライターは、悪意なく借用・偽装・過少申告という3種類の事故を起こす
- プロンプトで禁止するだけでは防ぎきれない(特に体験談の借用と自己申告の虚偽)
- 検収は**機械チェック(数えて判定)+出どころ突合(原本と突き合わせ)**の2本立てにする
- AIの「直しました」を信じず、こちらで実測する。これが品質管理の起点になる
- 人間ライターとは事故の種類が違うので、人間用の検収をそのまま流用しない
記事を読んで判断するのは人にしかできません。だからこそ、AIが起こす特有の事故は、人の注意力ではなく仕組みで止める。性善説のレビューを、数えて突き合わせる検収に変える。これが、AIライターを安心して回すための一番の近道でした。
AI×コンテンツ制作の品質体制を整えたい方へ
「AIに記事を書かせ始めたけれど、そのまま世に出していいのか不安」。そう感じているなら、止めるべきは出力です。プロンプトをいくら磨いても、借用や過少申告はすり抜けます。必要なのは、AI特有の事故を前提にした検収の仕組みです。
f2t.jpでは、AIを使ったコンテンツ制作の品質体制づくりをお手伝いしています。どこを機械でチェックし、どこを人が見て、何を原本と突き合わせるか。自社の本数・公開範囲・AIの使い方に合わせて、検収の線引きを一緒に整理するところから始められます。お問い合わせフォームから、「AIに書かせた記事の品質をどう担保するか」をご相談ください。
この記事のテーマに合うサービス:AIエージェント活用設計
AIエージェントを「使える形」まで設計する



