AIで作る量が増え、チェックが追いつかない。人間レビューを絞り込むAI出力評価の自動化

AIで作る量が増え、チェックが追いつかない。人間レビューを絞り込むAI出力評価の自動化
AIに記事や資料、コードを生成させる量が増えてくると、決まってこの壁にぶつかります。
> 「この出力、本当に出していいのか。結局、毎回人間が全部チェックしているから、AIで増やしたぶん人のチェックが追いつかない」
生成のスピードは上がったのに、その先で人間のレビューが詰まる。出力が10本になれば10本、100本になれば100本を誰かが読む。AIで作る量を増やすほど、人間レビューがボトルネックになり、品質もチェック担当者の気分やその日の余力でばらつきます。
ここで効くのが、AIの出力評価を自動化する仕組みです。生成するAIとは別のAIに、出来上がった成果物を観点ごとに採点させる。明らかな問題を機械的に弾いておけば、人間は「本当に判断が要るものだけ」を見ればよくなります。この記事は、AIで出力を量産しているがチェックが回らない、という状況の責任者に向けて、評価チェーンの組み方と向き不向き、そして人間レビューとの線引きをまとめます。
なお、AIエージェント組織を運用する全体像の品質管理は別記事にあります。本記事は組織や担当者の評価ではなく、生成された1つ1つの出力を出荷前にどう評価するかに絞ります。AIエージェント組織を6軸でスコアリングする品質管理は組織・エージェント単位の話、本記事は出力単位の話、という棲み分けです。
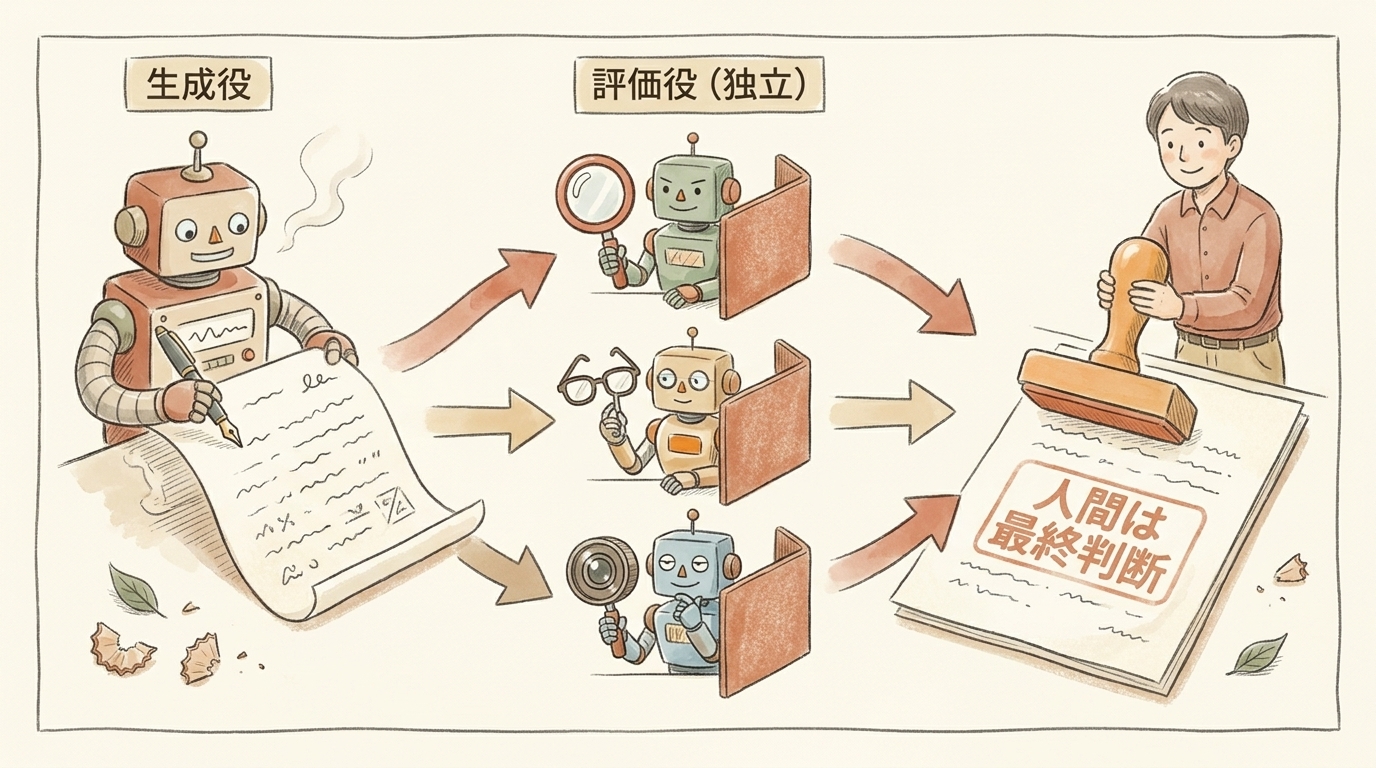
結論:生成役と評価役を分け、観点ごとに独立採点して人間レビューを絞る
要素を先に分解します。AIの出力評価を自動化する最小構成は、次の3つです。
部品 | 役割 | これが無いと |
|---|---|---|
生成役(Builder)と評価役(Grader)の分離 | 生成したAIとは別のAIに採点させる | 自分の出力に甘い採点になり、評価が形だけになる |
観点ごとの独立採点 | 事実性・品質・ポリシー遵守などを別々のAIが見る | 1つのAIに兼任させると見落としが増える |
ルーブリック採点+拒否権 | 評価基準のチェックリストで機械的に判定し、1つでも不可なら全体不可 | 採点がぶれ、止めるべき出力が通る |
軸はコストでも作りやすさでもありません。人間レビューのボトルネックを解消し、品質を安定させることです。評価を自動化する狙いは、人を置き換えることではなく、人が見る対象を「明らかに問題ない大量の出力」から「判断が要る一部」へ絞り込むこと。チェック担当者の負荷が下がり、出力が増えても品質のばらつきが抑えられます。
一番外してはいけないのは、生成したAI自身に自己採点させないこと。生成役は自分の出力を正当化しがちなので、評価は必ず別のインスタンス(=同じモデルでも会話の文脈を共有しない別の実行単位)に任せます。
Before / After:人間レビューの負荷と品質はどう変わるか

評価の自動化を挟む前と後で、現場の何が変わるかを並べます。
Before(全件を人間がチェック) | After(評価チェーンを挟む) | |
|---|---|---|
人間の負荷 | 出力が増えるほど読む量が増え、青天井 | 機械で弾いた残りだけ読む。要確認箇所に集中 |
品質のばらつき | チェック担当者の余力・気分・習熟で変わる | 同じ基準で毎回採点。下限が一定に揃う |
見落とし | 大量を流し読みするほど増える | 観点ごとに別AIが見るので、観点漏れが減る |
スケール | 出力10倍でチェックも10倍 | 出力が増えても人間が見る件数は緩やかにしか増えない |
止まり方 | 担当者が忙しい週はチェックが後回しになる | 採点は自動で回り、人間は判定済みの結果から見る |
人がやるべきは「これを出荷していいか」の最終判断であって、明らかなミスを大量に拾う作業ではありません。後者をAIの評価に任せ、空いた集中力を前者へ回す。これが評価チェーンを挟む狙いです。
ここで大事な注意があります。Afterの「見落としが減る」は「見落としがゼロになる」ではありません。評価の自動化は人間レビューの代替ではなく、人間が見るべき範囲を絞る前処理です。この線引きは後段で改めて強調します。
評価チェーンの中身:採点を直列につなぐ
実際に組む構成はこうなります。
```[Builder] 成果物を生成(例: 記事の下書き) ↓[Grader 1] 事実性をルーブリックで採点 → pass / fail ↓[Grader 2] 品質をルーブリックで採点 → pass / fail ↓[Grader 3] ポリシー遵守を採点 → pass / fail ↓[Auditor] 最終監査(高リスク観点)→ pass / 条件付き / fail ↓[最終判定] 全段passで初めて合格。1段でも不可なら止める```
各段は独立したAIインスタンスで、それぞれ専用のルーブリック(=評価基準のチェックリスト。項目を1つずつ満たすか判定する形式)を渡されます。評価役同士も互いの判定を見ません。事実性を見るAIとポリシーを見るAIが先行判定に引っ張られると、多数派に同調するバイアス(=前の採点に合わせてしまう偏り)が入るからです。観点を分けて独立させるほど、観点漏れが減ります。
この採点チェーンを組むうえで、運用して効いた設計上の肝が3つあります。
肝1:採点を3値にする
当初は採点を「合格 / 不合格」の2値で設計しました。運用すると、「合格だけど条件付き」という中間が要ると分かりました。
監査役が「重大な違反はないが、人間の確認は必須」と判断するケースです。これを2値に押し込むと、無理に合格にして条件が消えるか、不合格にして過剰に止まるかのどちらかになります。
そこで採点を3値にしました。
判定 | 意味 | 人間レビュー |
|---|---|---|
pass | 全段合格 | 任意 |
pass_with_conditions | 合格だが監査役が「要確認」を出した | 必須 |
fail | いずれかの段で不合格 | 差し戻し |
中間状態を表現できると、機械チェックと人間レビューの役割分担がはっきりします。人間が必ず見るのは pass_with_conditions と fail だけ。pass の大量の出力は確認を任意にできるので、レビューの母数そのものが小さくなります。
肝2:いつその採点を適用するかを定義する
採点項目には、タスクによって無関係なものがあります。「数値の正確性」を見るルーブリックは、文章の下書きには関係しません。実際に組んだとき、ある評価役は6項目中5項目が「該当なし」になり、ほぼ機能していませんでした。
そこで各ルーブリックに「いつ適用するか」を定義しました。
- 数値チェック:数値レポートやデータ集計のタスクのときだけ起動
- ポリシーチェック:公開コンテンツや外部送信を含むタスクのときだけ起動
タスク種別に応じて起動する採点を選ぶマトリクスを用意すると、無関係な評価で時間とAPI費用を無駄にしません。この適用条件を決めておくことが、評価の自動化を実用的な速度で回す鍵になります。
肝3:配信文脈を評価役に渡す
見落としがちな点です。同じ文章でも、どこに出すかで評価が変わります。
ある医療コラムの下書きを評価したとき、監査役が「このコラム自体は問題ないが、将来これを広告のランディングページに転用すると、規制に触れる表現になる」と指摘しました。コラムとして見れば合格、広告として見れば不合格。評価役に「これはどこに出すものか」を伝えないと、正しい判定ができません。
そこで評価役への入力に、配信文脈(コラム / 広告 / メルマガ / SNS / 内部資料)を必須項目として加えました。同じ成果物でも、文脈に応じて適用する基準が切り替わります。出力の評価を自動化するとき、何を出すかだけでなく「どこに出すか」まで渡すのが正確さの分かれ目です。
最重要の原則:AI採点は人間レビューを代替しない

ここがこの設計でいちばん大事なところです。これを外すと評価チェーンはむしろ危険な道具になります。
AIの採点が全段合格でも、それは人間の法務・専門レビューの代替にはなりません。医療・金融・法務のような間違いが許されない領域では、AIの評価はあくまで「人間が見る前に明らかな問題を弾く」段階にとどめます。
評価の自動化が生むのは、次の2つです。
- 人間が見るべき出力の下限品質を底上げする(明らかなミスを事前に除去)
- 人間レビューの負荷を減らす(全件精読ではなく、要確認箇所に集中)
人間を置き換えることではありません。この線引きを設計に明文化しておかないと、「AIが合格と言ったから大丈夫」という運用に流れます。それは、人間レビューのボトルネックを消そうとして、最後の安全網まで外してしまう失敗です。評価チェーンは網を絞り込む道具であって、網を外す道具ではない。ここは譲れません。
この「AIに任せる部分と、人が必ず握る部分を切り分ける」という発想は、出力評価チェーンに限らず、AIを業務に入れるとき全般の肝になります。少人数でもAIで量を捌きながら質を落とさない会社は、例外なくこの介入点を設計しています。組織全体での捉え方は「AIに任せて品質が落ちる会社と落ちない会社の違いは『介入点』にある」にまとめました。本記事はその出力評価版の具体編にあたります。
どの評価方式を選ぶか:負荷と見落としリスクで比べる
出力の品質を担保する方式は、評価チェーンだけではありません。代表的な選択肢を、人間の負荷と見落としリスクの軸で並べます。
方式 | 人間の負荷 | 見落としリスク | 向くケース |
|---|---|---|---|
全件を人間がレビュー | 高い。出力量に比例して青天井 | 低い(ただし流し読みが増えると上がる) | 出力が少量。1本ごとの重みが極めて大きい |
サンプリングレビュー(一部だけ抜き取り) | 低い | 高い。見ていない出力に問題が残る | 大量だが1本のミスの影響が小さい |
AI評価チェーン+人間最終確認 | 中。要確認分だけ人間が見る | 中。明らかな問題は弾けるが、判断が要るものは人間に回す | 出力が多く、品質を安定させたいが全件は読めない |
サンプリングは負荷こそ軽いものの、抜き取りから漏れた出力に問題が残るのが怖いところです。逆に全件レビューは見落としに強い反面、量が増えると担当者の集中力が持ちません。評価チェーンに人間の最終確認を組み合わせる方式は、その中間に立ちます。明らかな問題は機械が弾き、判断が要るものだけ人間が見る。出力が多く、品質を安定させたいが全件精読は現実的でない、という条件にいちばん合います。
安さや手軽さで選ぶのではなく、自社が抱える出力量と、1本あたりのミスがどれだけ痛いかで選んでください。
こんなケースには評価チェーンは向かない
無理に評価を自動化しないほうがいい場合もあります。正直なところを挙げます。
- 出力がそもそも少量:月に数本しか生成しないなら、評価チェーンを組む手間より人間が全部読むほうが速い
- ミスの影響が極めて重大:人命や巨額の損失に直結する出力は、AI採点を挟んでも最終的に人間の専門レビューが必須。自動化で人間を減らす前提が成り立たない
- 評価基準が言語化できない:何を良しとするかが担当者の暗黙知のままだと、ルーブリックに落とせず採点がぶれる。先に基準を言葉にする作業が要る
- 出力の形式がバラバラ:定型でない自由形式の出力ばかりだと、観点別採点の設計が重くなり、費用対効果が下がる
評価の自動化が効くのは、出力がそこそこの量で発生し、評価基準を言葉にでき、1本ごとのミスを「人間の最終確認で拾えればよい」と許容できるケースです。
導入前チェックリスト
評価チェーンの設計に入る前に、次を整理しておくと方針がぶれません。
- [ ] 評価したい出力は何か(記事 / 資料 / コード / 回答文 など)
- [ ] 月あたりの生成量はどれくらいか(評価を自動化する費用対効果が決まる)
- [ ] 評価の観点は何か(事実性 / 品質 / ポリシー遵守 / 数値の正確性 など)を言葉にできているか
- [ ] その出力はどこに出すか(配信文脈。コラム / 広告 / 社内資料 で基準が変わる)
- [ ] 高リスク領域か(医療・金融・法務なら、AI採点後の人間レビューを必須に固定する)
- [ ] pass_with_conditions と fail を誰が見るか(人間レビューの担当と差し戻しルートを決める)
この6つが決まれば、あとは前述の3部品(生成役と評価役の分離・観点別の独立採点・ルーブリック採点+拒否権)を組むだけです。
アンチパターン3つ
アンチパターン1:生成役に自己採点させる
生成したAIは自分の出力に甘くなります。評価は必ず別インスタンスに任せます。同じAIに「作ってから自分で採点して」とやらせるのは、評価をしているように見えて実態は素通しです。
アンチパターン2:採点を2値にする
合格 / 不合格だけだと「条件付き合格」を表現できません。3値にして、人間が必ず見るもの(条件付き・不合格)と任意でよいもの(合格)の役割分担を明確にします。
アンチパターン3:AI採点を人間レビューの代替にする
高リスク領域では、AIの評価はあくまで前段の品質底上げです。「AIが合格と言ったから」で人間レビューを省くと、ボトルネックを消すつもりが安全網を外すことになります。線引きを設計に明示します。
まとめ:評価を自動化して、人間は判断に集中する
AIの出力評価を自動化する設計は、次の5点に集約されます。
- 生成役と評価役を別インスタンスに分離する(自己採点させない)
- 観点ごとに独立採点し、1つでも不可なら全体不可(拒否権)
- 採点は3値(pass / 条件付き / fail)で、人間が見る対象を絞る
- タスク種別と配信文脈に応じて、適用する評価基準を切り替える
- AI採点は人間レビューを代替しない。高リスク領域では人間の最終確認を固定する
AIで出力を増やすほど、人間のチェックがボトルネックになり、品質もばらつきます。評価を自動化して明らかな問題を機械で弾けば、人間は「本当に判断が要るもの」に集中でき、出力が増えても品質の下限が揃います。鍵は、機械で弾けるものと人間が判断すべきものの線引きを、設計に最初から組み込むことです。
AI出力のチェックが回らなくなってきたら
「AIで作る量は増えたのに、結局うちの誰かが全部読んでいる」「チェックする人の余力で品質が変わってしまう」。そう感じ始めたら、出力の評価をどこまで自動化できて、どこからは人間が見るべきかの線引きを整理する時期です。
f2t.jpでは、AIエージェントの構築から、出力品質を担保する評価フローの設計(観点の洗い出し・ルーブリック作成・人間レビューとの役割分担)まで一貫してお手伝いしています。まずは「どの出力を・どれくらいの量・どんな観点で評価したいか」を一緒に整理するところから始められます。お問い合わせフォームから、自社のAI出力チェックの悩みをご相談ください。
この記事のテーマに合うサービス:AIエージェント活用設計
AIエージェントを「使える形」まで設計する



